-
Questa opera di Enrico Altavilla è concessa in licenza sotto la Licenza Creative Commons Attribuzione - Non commerciale - Non opere derivate 3.0 Unported.
Come calcolare la distribuzione del “PageRank” tra le pagine di un sito

Un’ottima descrizione del PageRank e della sua relazione con un sito web può essere data parafrasando le parole di Obi Wan Kenobi quando in Star Wars descrive il concetto de “La Forza“.
“Il PageRank è ciò che dà al sito la possanza. E’ un campo energetico creato da tutte le risorse. Le circonda, le penetra, mantiene unito tutto il sito.”
Non fatevi ingannare dal paragone apparentemente giocoso e superficiale: in realtà è davvero incredibile quanto la descrizione che ho appena dato combaci perfettamente con le caratteristiche della formula del PageRank.
Dal punto di vista matematico, il PageRank viene effettivamente creato da ciascuna risorsa, si accumula e si distribuisce tra esse in funzione delle relazioni che esistono tra loro ed è uno di quei segnali che conferiscono ai siti quella “possanza” che viene tenuta in considerazione da Google quando c’è da stabilire quanta visibilità concedere a tutti i siti web.
In questo articolo spiego come prendere visione del modo in cui il PageRank di un sito si distribuisce tra le sue pagine e sezioni, un’informazione che può aiutare a capire se un sito ha problemi di dispersione del PageRank o se lo distribuisce in modo non compatibile con gli obiettivi di business.
Non proprio PageRank
Ho virgolettato “PageRank” nel titolo perché la formula finale che utilizzerò non è realmente quella divulgata da Brin e Page nel 1998 ma una variante più generica chiamata Eigenvector Centrality (EC). Per essere precisi, il PageRank è una forma speciale di EC.
La ragione per la quale ho scelto EC è di ordine pratico: il software che userò per il calcolo ottiene valori più precisi rispetto a quelli che otterrei calcolando il PageRank.
(se non volete essere ammorbati da un approfondimento sulle due formule, saltate pure alla prossima sezione del post)
Le due formule differiscono principalmente per una delle caratteristiche matematiche del PageRank che l’hanno reso famoso, ovvero il fatto di suddividere la quantità di PageRank veicolata per la quantità di link presenti in una pagina. Questa differenza, tuttavia, non cambia di molto i risultati pratici che si ottengono quando le due forme vengono applicate ad un grafo come quello dei link interni di un sito web, perché la distribuzione di “importanza” all’interno di un sito è più che altro influenzata dall’architettura del sito stesso e da quelle strutture di navigazione (menu, sotto-meu, breadcrumb, paginazioni, ecc.) che vengono ripetute su una grande quantità di pagine.
Per dirla tutta, l’obiettivo di calcolare una distribuzione di importanza tra le pagine di un sito è in realtà perseguibile attraverso una qualunque formula che abbia l’obiettivo di stimare la “centralità” di un nodo, ovvero una probabilità che un utente vi possa arrivare in funzione dell’interlinking delle pagine.
Esistono alcune formule del calcolo della centralità che attribuiscono ad alcuni nodi dei valori di “importanza” poco in linea con quelli che verrebbero loro assegnati intuitivamente da un essere umano, ma PageRank ed Eigenvector Centrality sono entrambe formule che si comportano molto bene e che sono in grado di tener conto anche delle connessioni indirette tra i nodi.
Se volete approfondire la questione, trovate uno studio e paragone di alcune di queste formule nel documento Justification and Application of Eigenvector Centrality [PDF].
Infine, aggiungo che non avevo alcuna convenienza a replicare in modo fedele la formula originaria del PageRank, in quanto essa è per certo molto diversa e molto meno sofisticata di quella che Google utilizza oggidì.
Da questo punto in poi, fate conto che i concetti che esprimerò sul PageRank sono applicabili anche all’effettiva formula che poi utilizzerò durante i calcoli.
Questo non è un tutorial
Ho fatto il possibile per non trasformare questo articolo in un tutorial passo-passo, un po’ perché il metodo che sto per spiegare prevede diversi passaggi e sarebbe davvero impossibile dettagliarli tutti senza trasformare il post in un chilometrico listone di azioni, un po’ perché ho un’alta considerazione di chi mi segue da un po’ e do per scontato che il lettore riuscirà ad approfondire e personalizzare le mie indicazioni generiche a seconda delle proprie necessità.
In particolare, il software Gephi richiede certamente un po’ di pratica prima di poter essere usato con dimestichezza, essendo un software di una certa complessità. Non attendetevi quindi dal presente articolo una guida su Gephi, perché sarebbe impossibile e fuori luogo proporla.
Per facilitare al massimo gli “smanettamenti” ho provveduto a creare un archivio ZIP contenente tutti i file prodotti durante l’analisi (circa 3 megabyte). Spero che possa agevolare lo studio ed i test che vorrete fare sui vostri siti.
A che cosa serve questa analisi
Scoprire come il PageRank di un sito viene diviso tra le risorse che lo compongono, in funzione di come esse si linkano tra loro, è una delle analisi di base per individuare eventuali criticità SEO.
Nella stragrande maggioranza delle volte, si parla di PageRank solo in riferimento al segnale che contribuisce alla visibilità di una risorsa nelle SERP di Google. E’ però possibile acquisire importanti indicazioni sullo “stato di salute” del sito facendo anche paragoni tra i valori di PageRank attribuiti a ciascuna risorsa.
Quali sono le risorse del sito che ricevono maggiore PageRank? Esistono risorse particolarmente strategiche che ricevono troppo poco PageRank rispetto alle altre? Di contro, esistono risorse poco importanti a cui viene accidentalmente assegnato molto PageRank?
Una buona regola generale per comprendere se la distribuzione del PageRank è in linea con i propri obiettivi di business è quella di iniziare ad ordinare le risorse del sito per tipologia, decidere quanto ciascuna tipologia deve risultare visibile su Google in paragone alle altre (per esempio, ci sono classi di prodotti che sarebbe preferibile vendere più di altri?) e infine accertarsi che tali obiettivi di visibilità siano coerenti con la quantità di PageRank che i link interni del sito conferiscono a ciascuna tipologia di risorse.
Per la mia esperienza, le difficoltà riscontrate su alcuni siti ad ottenere visibilità per specifiche classi di query sono state a volte comprese proprio dando un’occhiata a come l’importanza veniva ripartita tra le risorse di diverso tipo.
L’analisi che sto per fare non deve focalizzarsi sui valori assoluti del PageRank di ciascuna risorsa bensì sulla percentuale di PageRank che esse ricevono.
Siccome l’obiezione più tipica che sento fare è che “tutte le risorse sono importanti“, mi tocca adesso spiegarvi perché questa logica è fuorviante…
La coperta troppo corta
Nessuna risorsa è infinita. Questo presupposto vale quando si allocano i budget, quando si definiscono gli investimenti su ciascun canale di marketing, quando bisogna ripartire le risorse a disposizione sulle attività necessarie a portare avanti l’azienda e quando è necessario decidere dove fare tagli alle spese. Questo concetto vale anche per il PageRank.
La semplice cosa da realizzare è che prendendo in considerazione uno specifico momento, la quantità complessiva di PageRank a disposizione di un sito è una quantità finita, e quindi va amministrata al meglio.
Se è pur vero che i siti che possiedono una quantità di PageRank maggiore sono in media più capaci di ottenere visibilità sulle SERP per insiemi di query più grandi, anche in quei casi è necessario farsi scrupolo di come attribuire importanza alle risorse del sito, perché ogni spreco o dispersione di importanza su risorse o sezioni del sito poco strategiche rappresenta comunque un’occasione persa per acquisire maggiore visibilità con le risorse che interessano di più.
Questa è la ragione per la quale più di una volta ho usato la metafora della coperta troppo corta: è irrealistico pretendere di coprire tutto in modo omogeneo ed è invece necessario essere selettivi, classificare le risorse del sito per reale importanza e accettare di sacrificare ciò che ci interessa meno per ottenere vantaggi di visibilità su quanto ci interessa di più.
Ingredienti
Per la ricetta che sto per illustrare è necessario dotarsi di alcuni ingredienti:
- Un crawler in grado di esportare l’elenco di link interni al sito. Io ho usato Screaming Frog SEO Spider.
- Un foglio di calcolo in grado di supportare un bel po’ di righe. Ho usato Excel.
- Un qualunque tool in grado di eliminare i doppioni da un elenco testuale di URL. Io ho usato un’opzione del text editor Ultraedit.
- Gephi, che è un software per la progettazione ed il disegno di grafi.
Metodologia
Per semplificare al massimo questa trattazione, ho deciso di applicare il metodo di calcolo della distribuzione del PageRank ad un sito molto piccolo e semplice, ovvero a LowLevel.it
Essendo LowLevel.it un blog personale, non strutturato come sarebbe un sito contenente una categorizzazione di prodotti o servizi, la quantità di considerazioni finali su quanto l’effettiva distribuzione del PageRank sia compatibile con gli obiettivi del sito sarà purtroppo molto limitata.
Date dunque per scontato che ha molto più senso applicare il metodo che sto per spiegare a siti ben più complessi e grandi, sopratutto siti che possiedono obiettivi di marketing e di business ben definiti.
Il modo in cui il PageRank viene distribuito tra le pagine del sito verrà determinato attraverso i seguenti passi:
- Effettuerò un crawling del sito per ottenere un elenco dei link interni
- Partendo dall’elenco di link otterrò un elenco di nodi (nodes) e archi (edges), ovvero il tipo di elementi di cui si compone un grafo
- Fornirò l’elenco di nodi ed archi a Gephi e calcolerò qualcosa di molto simile al PageRank, chiamato Eigenvector Centrality (EC)
- Dal calcolo, otterrò sia un indice di EC per ciascuna delle risorse del sito sia una rappresentazione visuale del grafo
- I valori di EC per ciascuna risorsa potranno essere poi utilizzati per calcolare valori medi di importanza di intere sezioni del sito
Il metodo che applico tiene conto di quanto viene effettivamente mostrato a Googlebot, di eventuali attributi nofollow su specifici link e di eventuali informazioni su URL canonici erogate attraverso l’attributo rel=canonical.
Il crawling del sito (Screaming Frog)
La prima fase dell’analisi consiste nel raccogliere i dati sui link interni al sito. Per questo scopo, ho utilizzato il crawler Screaming Frog.
In pura teoria sarebbe possibile usare in alternativa Xenu Link Sleuth ma poi sorgerebbero problemi con l’esportazione dei dati dei link, che in Xenu non è purtroppo configurabile per ottenere solo i link tra risorse HTML. Per ottenere dei dati finali più puliti potrebbero teoricamente essere applicati dei barbatrucchi in fase di configurazione iniziale del crawling ma anche attraverso questi espedienti è difficile ottenere un output 100% pulito. Inoltre Xenu non fornisce informazioni sull’eventuale attributo rel=canonical dei link. Per tutte queste ragioni ho escluso Xenu.
Il crawling di Screaming Frog va configurato nel seguente modo:
In Configuration > Spider > disabilitare il check di tutto ciò che non è HTML e accertarsi che l’opzione “Check External Links” non sia attiva, come dallo screenshot che segue.
In Configuration > User-agent > impostare Googlebot come user-agent
Importante: per siti molto grandi è anche suggerito limitare il crawling in modo che produca una quantità di URL finali non eccessivamente alta. Il problema non è tanto in Excel (che comunque possiede un limite massimo di righe in un foglio) quanto Gephi, che può diventare un po’ lento in presenza di grafi molto grandi. Consiglio quindi di usare l’opzione “Limit Search Depht” nella finestra di configurazione di Screaming Frog ed impostare una profondità di crawling tale che l’elenco di link finali non superi il centinaio di migliaia, un limite che potete modificare a vostra discrezione in base alle prestazioni del vostro computer. Vi consiglio quindi di fare delle prove per comprendere fino a che punto la vostra macchina comincia ad avere problemi a gestire grandi quantità di dati.
A questo punto il crawling può iniziare e, una volta terminato, è necessario esportare due tipi di dati: l’elenco dei link trovati dallo spider e un elenco degli URL che includa l’indicazione dei loro eventuali URL “canonical”.
E’ possibile esportare l’elenco dei link attraverso l’opzione di menu “Advanced Export > All links”. Avendo configurato il crawling perché non seguisse link esterni, il risultato sarà un file CSV contenente solo i link interni al sito.
L’esportazione di un elenco degli URL che includa anche l’indicazione di eventuali attributi “canonical” può essere fatta selezionando il tab “Internal”, selezionando la voce “HTML” dalla lista “Filter” e cliccando sul pulsante “Export” per salvare il file CSV.
Ripulire i dati (Excel)
Prima di passare alla fase di preparazione dei dati nel formato accettato da Gephi, è necessario svolgere alcune piccole operazioni di “ripulitura” di quanto Screaming Frog ha esportato.
Siccome su diversi passaggi andrò veloce, vi suggerisco di chiarirvi le idee osservando il risultato finale nel file Excel presente nell’archivio ZIP linkato in cima a questo articolo.
I due file CSV esportati da Screaming Frong vanno innanzitutto importati in due schede di un foglio Excel; potete chiamare la prima “All links” e la seconda “Canonical info”, perché l’elenco degli URL servirà esclusivamente ad estrarre gli eventuali contenuti degli attributi rel=canonical.
Alla scheda “All links” vanno aggiunte due colonne: a fianco della colonna “Source” va aggiunta una colonna “Source Canonical” e a fianco della colonna “Destination” va aggiunta una colonna “Destination Canonical”. Per ciascuna riga del foglio, queste due nuove colonne conterranno gli URL canonici corrispondenti a quelli presenti in “Source” e “Destination”, che potete estrarre dalla scheda “Canonical info” usando la formula della ricerca verticale (CERCA.VERT o, in inglese, VLOOKUP).
Le pulizie di primavera della scheda “All links” avvengono svolgendo tre semplici passi:
- eliminazione dei link (cioè righe) da/verso risorse palesemente non HTML ma erroneamente dichiarate HTML dal server
- eliminazione dei link verso risorse che fanno redirezioni
- eliminazione dei link con attributo rel=nofollow
Risorse erroneamente dichiarate dal server come HTML possono essere facilmente individuate dando un’occhiata all’estensione dei file, le redirezioni si riconoscono perché Screaming Frog indica per ogni URL lo status HTTP restituito dal server e l’attributo rel=nofollow è individuabile perché, anche in questo caso, Screaming Frog crea un’apposita colonna contenente questa informazione.
Queste appena elencate sono le azioni che si sono rese necessarie per minimizzare il problema della duplicazione dei contenuti e quello dei link nofollow, che per definizione sono quei link per i quali Google non crea un arco nel link graph.
Applicata a siti più complessi, questa procedura di ripulitura potrebbe richiedere ulteriori passaggi, a seconda del tipo di risorse che Screaming Frog avrà incontrato e a seconda delle impostazioni del server o del CMS.
Preparare i dati per Gephi (Excel)
Gephi richiede che i dati del link graph gli vengano forniti sotto forma di due elenchi: un elenco di nodi, che nel nostro caso corrispondono all’elenco di risorse del sito, e un elenco di archi, ovvero di link che puntano da una risorsa all’altra.
Per creare l’elenco di nodi ho usato un semplice text editor: ho creato un file con l’elenco dei contenuti delle colonne “Source Canonical” e “Destination Canonical” ed ho eliminato tutti i duplicati. Questa lista è stata poi inserita in una nuova scheda del file Excel chiamata “Nodes” e a ciascun URL è stato attribuito un ID numerico univoco, semplicemente numerando gli URL da “1” in poi, ed un’etichetta, che per semplicità ho fatto corrispondere con il percorso della risorsa, privo del nome di dominio. Il risultato finale è presente nella scheda “Nodes” del file Excel che ho allegato all’articolo, che ho poi interamente esportata in formato CSV.
Per creare l’elenco di archi ho aggiunto un’ulteriore scheda al file Excel e l’ho chiamata “Edges”. Quello che trovate all’interno dell’esempio allegato non è altro che una trasposizione dei link presenti nella scheda “All links” usando gli ID delle risorse che sono stati creati nel passaggio precedente e che sono presenti nella scheda “Nodes”. Anche questa scheda è stata poi esportata in formato CSV. Fate bene attenzione che per poter essere importati in Gephi, i nomi delle due colonne devono categoricamente essere “Source” (pagina linkante) e “Target” (pagina linkata).
Nell’archivio ZIP a corredo trovate per vostra comodità anche i due file CSV esportati, relativi ai nodi e agli archi del grafo.
Importare i dati su Gephi
Creati i due file CSV che contengono rispettivamente l’elenco di nodi e di archi del grafo, è necessario importarli su Gephi.
Lanciato il software e creato un nuovo progetto attraverso l’apposita opzione del primo menu, è necessario spostarsi nella sezione “Data laboratory”, cliccare sul pulsante “Nodes” e poi su “Import Spreadsheet” per importare il file CSV contenente l’elenco dei nodi del grafo. Si aprirà una finestra di dialogo attraverso la quale dare il via all’importazione. Trovate i dettagli di utilizzo della finestra in questa pagina del manuale di Gephi.
Allo stesso modo, sarà possibile importare gli archi del grafo cliccando sul pulsante “Edges” e poi su “Import Spreadsheet”. Per i dettagli fate sempre riferimento alla pagina del manuale sopra linkata.
Attribuire l’importanza alle risorse
Adesso che i dati del grafo sono stati importati in Gephi, è possibile calcolare finalmente l’importanza di ciascun nodo.
Per lanciare il calcolo è sufficiente spostarsi sulla scheda “Overview” cliccando l’apposito pulsante in alto a sinistra della finestra di Gephi, accedere al pannello “Statistics”, che è presente all’estrema destra della finestra e cliccare sul pulsante “Run” a fianco di “Eigenvector Centrality”, che aprirà una finestra di dialogo sulla quale sarà sufficiente confermare il comando cliccando su “Ok”. Lo screenshot seguente dovrebbe chiarire eventuali dubbi.
Una volta calcolato l’EC dei nodi del grafo, viene aggiunta una colonna all’elenco dei nodi importati durante la fase precedente. Questa nuova colonna è chiamata “Eigenvector Centrality” e contiene il valore di EC di ciascun nodo.
Se siete abbastanza smanettoni potete esportare in formato CSV la lista dei nodi, che adesso è completa dell’EC di ciascun nodo, ed importarla su un foglio di calcolo per fare le vostre proprie considerazioni su come il linking interno attribuisce importanza a ciascuna risorsa del sito. Ecco come appare l’elenco una volta importato su Excel:
Organizzare il grafo
Questo articolo non sarebbe completo se non vi indicassi, quantomeno in modo abbozzato, come visualizzare il grafo.
Gephi mette a disposizione molte tecniche per conferire automaticamente un layout al grafo ma i risultati migliori possono essere ottenuti definendo manualmente le caratteristiche visuali dei diversi elementi che compongono il grafo.
Nello specifico caso dei link si un sito io vi suggerisco di procedere come segue:
- usate il box “Ranking” presente in alto a sinistra per conferire un colore ed una grandezza diversi a ciascun nodo in base al suo valore di EC. Io ho fatto in modo che i nodi con maggior valore di EC fossero più grandi e di colore azzurro, a differenza dei nodi meno importanti, che sono gialli e di dimensioni più piccole.
- usate il box “Layout”, sottostante a quello “Ranking” per organizzare i nodi secondo un criterio. Io ho posto al centro del grafico i nodi più importanti lanciando in sequenza tre diversi algoritmi: Random Layout, Fruchterman Reingold e Label Adjust.
Il risultato dovrebbe essere qualcosa di simile allo screenshot che segue; ma molto più probabilmente no, perché Gephi è abbastanza incasinato e la probabilità che abbiate ottenuto lo stesso mio risultato partendo da generici suggerimenti è prossima a zero.
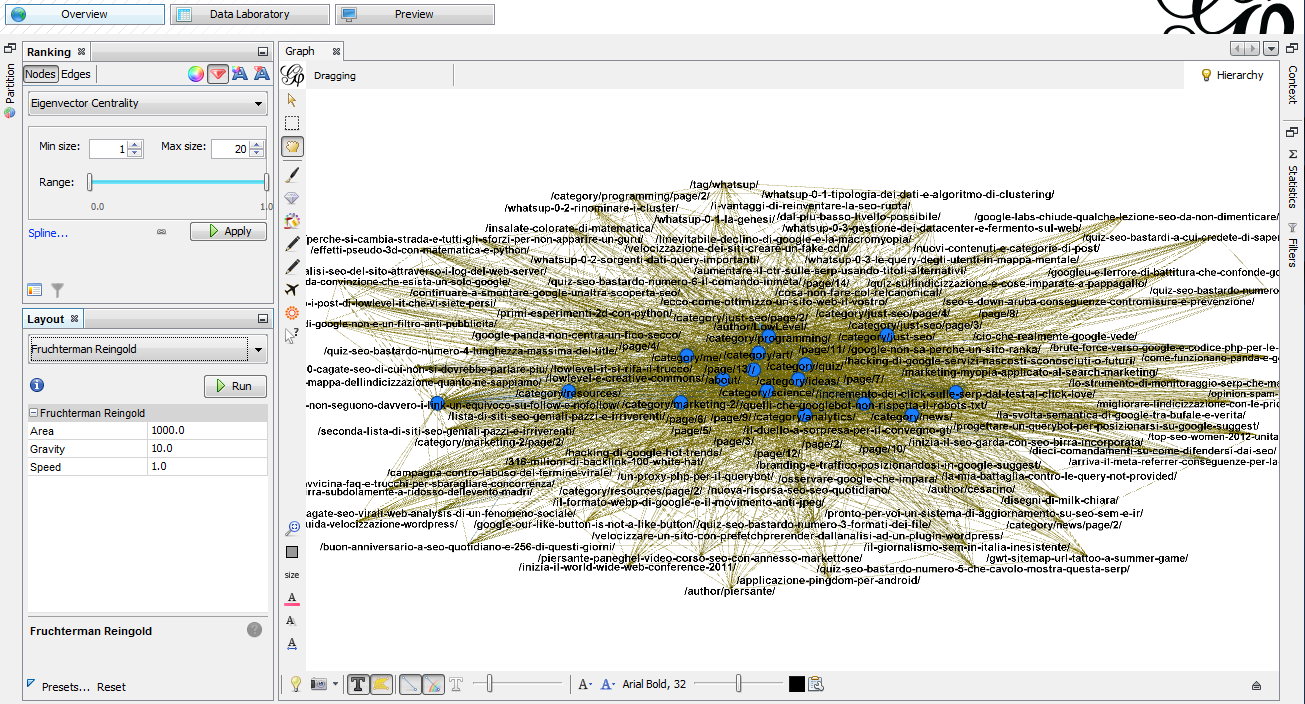
Notate che l’anteprima grafica ottenuta è di tipo interattivo e che è possibile modificare singoli elementi usando il mouse e diversi strumenti di disegno. Potete considerare Gephi una sorta di “Photoshop” dedicato ai grafi, quindi le possibilità di personalizzazione di layout e caratteristiche visuali sono sostanzialmente illimitate.
Creare una preview
Una volta ottenuta un’anteprima grafica accettabile, è possibile passare alla fase di rendering vera e propria, cliccando sul pulsante “Preview” posto in cima alla finestra.
Siccome anche in questa sezione del software la quantità di opzioni è da mal di testa, a fornirvi delle indicazioni puntuali non ci penso nemmeno, anche perché nell’archivio ZIP allegato al post trovate il file in formato Gephi del progetto, in cui sono già attive tutte le opzioni della sezione “Preview” che hanno dato vita all’immagine finale.
Vi invito quindi a smanettare da voi con le varie voci che servono a definire gli aspetti del disegno finale e mi limito ad evidenziarvi un’opzione molto utile nel caso di grafi molto grandi: “Preview ratio”, presente in fondo alla colonna “Preview Settings”, che è in grado di sfoltire un po’ la quantità di nodi ed archi visualizzati nel grafico finale per renderlo meno confusionario.
Ottenuto il risultato desiderato, è possibile esportare un’immagine attraverso il pulsante “Export: SVG/PDF/PNG” posto sotto lo slide “Preview ratio”.
Vi lascio con un’immagine di ciò che ho ottenuto io ma vi invito a non spendere troppo tempo in queste quisquilie visuali perché a mio parere l’attività più utile ed interessante verrà spiegata nella sezione seguente dell’articolo.

L’importanza delle sezioni
Come indicato nella sezione “Attribuire l’importanza alle risorse”, una volta calcolato l’Eigenvector Centrality di ciascun nodo è possibile esportare l’elenco di nodi da Gephi in formato CSV ed importarlo su Excel per svolgere tutte le considerazioni del caso.
La prima attività che mi sento di suggerire è quella di calcolare l’EC medio di intere sezioni del sito. Purtroppo il sito analizzato in questo articolo non è sufficientemente complesso per proporre un esempio pratico, ma nel caso di siti ben organizzati in categorie e sottocategorie risulta abbastanza facile calcolare indici di importanza di interi gruppi di risorse.
Per esempio, se le risorse del sito sono in qualche modo classificabili per tipologia attraverso una caratteristica dell’URL, sia essa il nome di una directory o la presenza di un parametro, potete creare una colonna sul foglio di calcolo destinata ad accogliere un’indicazione del tipo di risorsa e poi calcolare l’EC medio di ciascuna tipologia di risorsa attraverso una tabella pivot o anche per mezzo di semplici formule.
Ottenere un indice di importanza media di intere sezioni del sito o di intere tipologie di risorse accomunate da una medesima caratteristica è la ragione principale per la quale svolgo il tipo di analisi che ho spiegato in questo articolo. Attraverso la metodologia appena delineata mi è possibile comprendere velocemente se il linking interno del sito ripartisce l’importanza tra le risorse in modo coerente con le risorse che si desidera effettivamente rendere più visibili nei risultati dei motori di ricerca.
Più il linking interno di un sito web è complesso e più è facile non cogliere ad occhio nudo quelle caratteristiche delle strutture di navigazione che, sommate, possono influre pesantemente sul modo in cui l’importanza viene distribuita all’interno del sito. E’ questa la ragione per la quale all’inizio di questo post indicavo che un’analisi come quella spiegata acquisisce sempre più senso al crescere della complessità dell’architettura e del linking di un sito web.
Vale anche la pena di aggiungere che in pochi casi mi è capitato di valutare esempi di progetti di siti web in cui i link interni venissero pensati prendendo in considerazione gli obiettivi di usabilità. Per quella che è la mia esperienza, in fase di progettazione ho sempre notato la tendenza ad inserire link a destra e a manca, seguendo criteri generici e posticipando a future analisi di usabilità il compito di determinare se quei link avevano effettivamente senso di esistere nella forma e nel modo in cui erano stati pensati. Un’analisi come quella illustrata può quindi rivelarsi un ottimo aiuto a comprendere meglio gli effetti dell’organizzazione dei contenuti già in fase di progettazione del sito, prima che lo stesso venga reso pubblico.
Eccezioni alla regola
Dando un’occhiata all’elenco dei valori di EC vi verrà spontaneo notare che tra le pagine che ricevono una maggiore quantità di importanza ci sono anche quelle tipicamente “di servizio”, come la pagina della privacy o qualsiasi risorsa che riceva un link site-wide.
Il modo poco furbo di reagire a questa evidenza è quello di farsi prendere dal panico e applicare ciecamente attributi “nofollow” ai link verso queste pagine, oppure andare di mannaia con la direttiva “Disallow” nel robots.txt.
Ovviamente quelle contromisure non servono assolutamente a nulla, men che meno a “recuperare PageRank”. Il modo intelligente di reagire alla presenza di pagine secondarie con tanta importanza è invece quello di ricordarsi che un portavoce di Google ha detto esplicitamente in passato che gli ingegneri sono perfettamente consapevoli di questo fenomeno universale e che sono stati presi provvedimenti affinché quel tipo di pagine di servizio non corrano il rischio di essere percepite molto importanti, nonostante i link site-wide.
Questo aspetto mi dà modo di sottolineare di nuovo il modo corretto in cui l’analisi della distribuzione del PageRank va svolta: non focalizzatevi su valori assoluti e su risorse specifiche, cercate piuttosto di valutare l’importanza media di gruppi di risorse dalle caratteristiche comuni.
Conclusioni
In questo articolo ho cercato di condividere una modalità per accertarsi che i contenuti di un sito siano organizzati e raggiungibili in misura proporzionale all’importanza che gli si vorrebbe assegnare.
La metodologia proposta è solo una delle tante possibili soluzioni che potrebbero essere ideate per assolvere allo stesso compito, pertanto mi auguro che il metodo abbia almeno svolto la funzione di “food for mind” e che vi possa tornare utile prima o poi.
Come al solito, i commenti sono a disposizione di tutti per eventuali richieste di chiarimenti e per approfondire qualche aspetto. 🙂
Contenuto del file ZIP
- Lowlevel-it-crawl.seospider: il file di Screaming Frog con il crawling del sito
- Lowlevel-it-all_links.csv: il file con l’esportazione di tutti i link del sito
- Lowlevel-it-internal_html.csv: il file con l’esportazione degli URL interni al sito
- Lowlevel-it-crawl.xlsx: il file Excel in cui ho organizzato i dati
- Lowlevel-it-nodes.csv: il file con l’elenco di nodi da fornire a Gephi
- Lowlevel-it-edges.csv: il file con l’elenco degli archi da fornire a Gephi
- Lowlevel-it.gephi: il file di Gephi con il grafo del sito
P.S.
Pensavo che sarebbe interessante parlare di argomenti simili in qualche evento. Giusto per dire.
Secondo te, il software gephi potrebbe essere utilizzato per fare analisi netnografiche a scopo seo?
@Francesco: direi proprio di sì, tenuto conto che diversi algoritmi e statistiche già predisposti in Gephi sono solitamente usati per analisi di network sociali. Quando scrissi questo post sull’analisi dei tweet non usavo ancora Gephi e feci tutti i calcoli a mano, però Gephi sarebbe stato un eccellente software per svolgere quell’analisi.
Avrei messo un link al file da scaricare anche in fondo. Per il resto, francamente come geek mi piace molto quel che hai fatto, ma da un lato pratico sono perplesso che molto di quello che si potrebbe ottenere non darebbe beneficio al cliente medio che non capirebbe nemmeno perche’ hai speso 4 ore per fare una cosa del genere.
@Seoer: dal mio punto di vista non esistono “medicine standard per pazienti medi”. 🙂
A seconda di quello che serve nello specifico caso, si decide di svolgere o meno questa analisi, che richiede dai 15 ai 30 minuti di tempo (nella versione più semplice) .
Il concetto lo si può estendere a qualsiasi tipo di analisi: si fa se ha utilità in uno specifico contesto.
Enrico, complimenti. Come sempre, ottimo post!
Domanda: secondo te ha senso comparare in qualche modo i risultati ottenuti da questo tipo di analisi con quelli ottenuti analizzando gli accessi da Googlebot al sito (quello di cui parlavi qui, per intenderci http://www.lowlevel.it/lanalisi-seo-del-sito-attraverso-i-log-del-web-server/).
E nel caso i risultati fossero “parecchio” diversi (nel senso risorse con EC elevato e poco crawling/viceversa)???
Grazie anticipatamente, e complimenti ancora.
Simone
@Simone: ciao. Tenuto conto che la profondità e la frequenza del crawling avviene grosso modo seguendo la distribuzione del PageRank, potrebbe avere un senso fare un paragone.
All’atto pratico è comunque necessario riconoscere quali comportamenti di Googlebot non sono un indice di importanza delle pagine richieste (per esempio i task di “deep crawling” che ogni tanto vengono effettuati sull’intero sito) e prendere in ogni caso i risultati del paragone cum grano salis.
L’unica volta che ho fatto un paragone simile, i due risultati effettivamente combaciavano molto bene. Ma sarebbe necessario comparare molti più casi per stabilire se si è trattato di un’eccezione o se la coerenza tra crawling ed EC rappresenta la norma.
Se ci provi tu, facci sapere attraverso i commenti. 🙂
Grande Articolo, come sempre 🙂
Dal mio punto di vista manca solo un appunto: tra “L’importanza delle sezioni” e “Eccezioni alla regola” avrei messo “l’utente, la probabilità di click e la distribuzione del Pagerank”.
Nessuno mai sarà in grado di tirare fuori un dato che si avvicini a quello di Google: ovvero anche con L’analisi dei dati in Page, Il flusso dei visitatori, le visite di Google Analytics o altri saremo in grado di assegnare un punteggio all’importanza di un link all’interno della pagina in relazione alla struttura del sito.
Se dovessi per esempio analizzare Pinterest, almeno sarebbe da settare un valore molto più alto ai link tramite le immagini.
Noi siamo passati nel SEOBlog a uno stile simile, magari la strutturazione dei link è identica, ma la probabilità di click sugli articoli ora è totalmente cambiata!
Come si fa? 😀
Articolo molto interessante e anche l’unico che abbia letto che esponga un metodo pratico per valutare i link interni ad un sito. Però mi sorge una domanda: questo metodo attribuisce valori identici a tutti i tipi di link: menù, footer, widget laterali, testo dell’articolo, mentre è prassi piuttosto comune attribuire un valore maggiore ai link contenuti nel contenuto principale, ed un valore minore ai link sitewide. Secondo te ha senso oppure i link valgono tutti uguali, come questa tipologia di analisi suggerisce?
Ciao Davide. Risposta breve: no, la metodologia fa uso della formula originale del PageRank, non delle varianti moderne, di cui non si conosce la formula e che sicuramente prendono in considerazione anche la posizione dei link.
Tuttavia se ci fosse modo di acquisire un indice di visibilità del link all’interno di ciascuna pagina, sarebbe facile usarlo come valore da dare a Gephi per attribuire un peso diverso a ciascun edge. In questo modo, il calcolo sarebbe un po’ più in linea con ciò che Google fa oggi.
La metodologia discussa nell’articolo, pertanto, continua ad avere valore solo se comparata con metodologie più semplici, per esempio quelle che attribuiscono lo stesso peso a tutti i link. Comparata invece con ciò che Google effettivamente fa oggi (su cui c’è solo mostero), va invece considerata sicuramente imprecisa.