-
Questa opera di Enrico Altavilla è concessa in licenza sotto la Licenza Creative Commons Attribuzione - Non commerciale - Non opere derivate 3.0 Unported.
L’analisi SEO del sito attraverso i log del web server
Quanti di voi si sono dedicati almeno una volta all’analisi dei log del web server nel tentativo di capire come gli spider dei motori perlustrano un sito web?
La mia impressione è che questo genere di analisi fosse più comune in passato che non oggi, eppure osservando i comportamenti degli spider è possibile osservare possibili criticità e persino trarre informazioni sull’opinione che un motore di ricerca si è fatto di un sito web. I log sono utili anche per altri scopi, per esempio di web analysis, ma questo esula dal tema del presente post.
Questo articolo nasce da un breve post sull’argomento scritto tempo addietro su Google+. Martino Mosna mi chiedeva perché non ne facevo un articolo per il blog ed io non ritenevo che i contenuti fossero particolarmente interessanti.
Di conseguenza ho deciso di riscriverli e arricchirli, aggiungendo anche i risultati di una reale analisi SEO che ho svolto qualche mese fa, penso che alla fine sia venuto fuori qualcosa di potenzialmente utile.
Tutto ciò che segue fa riferimento al motore di ricerca Google e allo spider Googlebot dedicato all’indice Web. Alcune delle considerazioni fatte possono essere estese attraverso il (vostro) sano buonsenso anche agli spider di altri motori di ricerca.
Introduzione

L’analisi dei file di log del web server è un pezzo del vasto puzzle delle analisi SEO e può fornire indicazioni molto utili. Per esempio è possibile capire:
- se c’è qualcosa che non va nella navigazione interna del sito
- quanto velocemente lo spider reagisce alla pubblicazione di nuove risorse
- se lo spider mostra poco interesse nei confronti di risorse strategiche e che è importante far indicizzare
- se lo spider mostra troppo interesse nei confronti di risorse non strategiche e che è secondario che vengano indicizzate (sopratutto perché la banda assegnata da Google al sito non è infinita ed è corretto ottimizzarla)
- quali sezioni del sito vengono perlustrate di più e quali vengono invece snobbate
- quanta importanza Google effettivamente assegna al sito web e quanto il motore è “ingordo” dei suoi contenuti. La capacità di percepire correttamente questo fenomeno non è una scienza esatta ed è possibile raggiungerla dopo un po’ di pratica e dopo aver acquisito una chiara comprensione di tutti i differenti tipi di comportamenti dello spider.
Le basi ma veramente basi del crawling di Googlebot
Leggete la seguente documentazione e fatene il vostro breviario: https://developers.google.com/webmasters/control-crawl-index/
Le basi del crawling di Googlebot
Le modalità di scansione dei siti da parte di Googlebot variano grandemente da sito a sito. I fattori che determinano queste differenze sono principalmente i seguenti:
- L’importanza assegnata da Google a ciascuna risorsa
- La grandezza del sito, in termine di risorse
- La profondità del sito
- L’architettura dell’informazione
- L’unicità delle risorse
- La frequenza di pubblicazione di nuove risorse
- La frequenza di aggiornamento delle risorse già esistenti
- L’uso di redirezioni e la quantità di risorse inesistenti
- La presenza di status d’errore del web server
- La velocità del sito ad erogare le risorse
- La quantità massima di banda che Google ha deciso di dedicare al sito
E mo’ ci tocca dettagliare questi aspetti uno per uno.
L’importanza assegnata da Google
Il PageRank è dichiaratamente (video di Matt Cutts sul PageRank) il principale fattore su cui Google si basa per decidere quanto andare a fondo nella perlustrazione di un sito.
Si può semplificare la faccenda affermando che una risorsa considerata più importante da Google indurrà maggiormente Googlebot a seguire i link che la risorsa stessa contiene.
Questa caratteristica assume un ruolo decisivo sopratutto per quei siti web che presentano livelli di profondità gerarchica molto alta o strutture di linking interno particolarmente vaste.
Importante: il messaggio di fondo di questo articolo è proprio quello che la stretta relazione che esiste tra crawling e PageRank permette di capire quanto il sito gode di buona reputazione agli occhi del motore osservando semplicemente come esso viene perlustrato dai crawler. Le informazioni che seguono vi servono per avere visibilità di tutti quei fenomeni che influiscono sul crawling, sia quelli che sono correlati all’importanza che il motore assegna alle risorse sia quelli che non devono essere confusi come segnali correlati all’importanza delle risorse. Se riuscirete ad acquisire questa capacità di analisi, una veloce occhiata ai log del server vi potrà venire d’aiuto in più di un’occasione per chiarirvi le idee sul rapporto tra sito e Google.
La grandezza del sito
Solitamente l’obiettivo dello spider è quello di ottenere un’immagine quanto più possibile completa e aggiornata del sito web. A volte tale desiderio è debole o viene a mancare nel caso di siti che Google non percepisce particolarmente importanti, tuttavia l’obiettivo ideale e teorico del motore rimane quello.
La quantità di risorse pubblicate sul sito rappresenta quindi una delle principali caratteristiche che inducono lo spider a perlustrare più ampiamente i contenuti: più lo spider individua nuovi contenuti, più sarà incentivato a proseguire e più il sito riceverà accessi ogni qualvolta lo spider vorrà controllare che le risorse siano sempre al proprio posto e se i loro contenuti sono cambiati dall’ultimo accesso.
La profondità del sito
Il concetto più semplice di profondità di una risorsa coincide con il numero di click da fare per raggiungere la risorsa partendo dalla home page.
Come vedremo di seguito, questo tipo di profondità non è l’unica esistente dal punto di vista del motore di ricerca.
Per il momento ci basta sapere che nella stragrande maggioranza dei casi, lo spider deve essere incentivato a perlustrare un livello gerarchico inferiore a quelli che ha già scandagliato.
L’architettura dell’informazione
Per ottenere una visione completa delle caratteristiche che motivano il motore a scandagliare un sito non bisogna mai dimenticare che uno dei suoi obiettivi è quello di costruirsi un grafo del sito stesso, ovvero una mappa del suo linking interno.
L’architettura dell’informazione dunque influisce pesantemente sul tipo di grafo che verrà fuori e su come il PageRank verrà distribuito tra le risorse, con le conseguenze che potete immaginare tenendo in considerazione quanto già scritto nella sezione “L’importanza assegnata da Google”.
L’unicità delle risorse
Tranne eccezioni, se Googlebot individua continuamente copie di risorse che già possiede o nota la presenza di risorse sostanzialmente prive di contenuti, allora sarà poco incentivato a seguire la stessa categoria di link che lo hanno condotto alle risorse considerate di bassa qualità.
Ho scritto “tranne eccezioni” perché più in fondo darò evidenza di tali casi particolari.
La frequenza di pubblicazione
La frequenza di pubblicazione di nuove risorse rappresenta un incentivo per Googlebot a tornare sul sito web in cerca di novità.
La frequenza di aggiornamento
Anche la frequenza con la quale le risorse esistenti vengono aggiornate può rappresentare un incentivo per lo spider a ritornare spesso sulle stesse pagine, a volte per individuare contenuti nuovi o modificati, altre volte per controllare se sono stati pubblicati nuovi link.
Redirezioni e risorse inesistenti
Le redirezioni comportano un incremento delle richieste fatte dallo spider al web server, in quanto a ciascun accesso all’URL “vecchio” corrisponde anche un accesso al “nuovo” URL di destinazione della redirezione. Questa caratteristica è maggiore nel caso in cui le redirezioni siano di tipo temporaneo (status HTTP 302 e 307) perché Googlebot (ed i client HTTP in genere) mantengono come riferimento l’URL che effettua la redirezione temporanea, non quello della risorsa di destinazione.
Riguardo le risorse inesistenti (status HTTP 404 e 410) bisogna ricordare che i loro URL vengono saltuariamente ricontrollati dagli spider, specie se sul Web esistono ancora link che puntano ad essi. E’ dunque errato credere che una risorsa 404 non generi più richieste da parte di Googlebot: un saltuario controllo di tali URL viene comunque mantenuto.
Errori del web server
Gli status di errore HTTP della famiglia 5xx sono quelli previsti dal protocollo per comunicare errori del web server, solitamente di natura tecnica.
Alla presenza di errori di questo genere, i comportamenti degli spider possono variare considerevolmente, a cominciare dalla frequenza delle richieste. Alcuni fenomeni sono inoltre particolarmente subdoli, per esempio quello di un errore di classe 5xx associato al file robots.txt del sito (un tema ultimamente gettonato a causa di un intervento mio e di Cesarino Morellato ad un Convegno GT, già aggiunto alla lista di argomenti su cui scrivere un post).
Le richieste di URL che restituiscono uno status di errore del web server inducono di norma gli spider a richiedere la URL stessa fino a quando essa smetterà di restituire errori.
Velocità del sito
Se il sito è lento ad erogare le risorse, Googlebot eviterà di chiederne molte.
Lo spider è infatti progettato per evitare di inondare i server web di richieste che potrebbero “ingolfarli”. Questo fenomeno può accadere se lo spider è troppo veloce ad effettuare richieste e/o se il server è troppo lento ad erogare le risorse chieste.
Come conseguenza, Googlebot adatta dinamicamente la propria frequenza di richieste a seconda di quanto il server web è in grado di soddisfarle in fretta.
Massima banda concessa
L’osservazione mi ha portato a concludere che esista comunque una quantità massima di attenzione (si legga: banda) che il motore di ricerca è disposto a concedere al sito web.
Applicando buonsenso e logica informatica, sarei indotto a credere che tale quantità massima di attenzione concessa sia una semplice conseguenza della combinazione di tutti i fattori sopra elencati. Tuttavia il concetto che è importante tenere a mente è che, a prescindere dalla causa, esiste una quantità massima di banda che lo spider consumerà durante uno specifico lasso di tempo (es: 24 ore).
Questo implica che è importante indurre lo spider a scaricare le risorse che più ci interessa far indicizzare, cercando di minimizzare il più possibile gli sprechi di banda legati allo scaricamento di risorse non importanti.
Mettere tutto assieme
Va da sé che che ciascuno dei fattori sopra elencati non ha valenza a sé ma influisce sul comportamento di Googlebot solo quando viene messo in relazione con tutti gli altri.
Sarebbe quindi errato dedurre che è sufficiente ottimizzare uno di quei fattori per migliorare (quantomeno dal punto di vista quantitativo) il crawling dell’intero sito.
L’unico fattore che realmente può influire da solo e facilmente su tutti gli altri è quello della velocità del sito, nel senso che un sito eccessivamente lento induce immediatamente lo spider a ridurre pesantemente la quantità di richieste.
Concetti chiave e comportamenti tipici di Googlebot
Nei paragrafi precedenti ho fornito un elenco di fattori che concorrono a determinare quante e quali risorse verranno richieste dallo spider, adesso darò invece evidenza di alcuni concetti chiave del crawling.
Velocità di scoperta degli URL
Google è in grado di scoprire nuovi URL in modo molto veloce, usando più di un metodo. Nuovi URL possono essere scoperti attraverso i link sul web, per mezzo dei ping esplicitamente inviati al motore, in feed e sitemap XML e dai tanti segnali generati dalle azioni degli utenti.
In linea teorica, se un sito ha nei propri backlink il principale canale per far scoprire agli spider i nuovi URL, allora la velocità con cui Googlebot si rende conto della nascita dei nuovi URL può essere considerata un indicatore molto grezzo di quanto il motore di ricerca considera il sito importante.
Nella pratica, molti siti web possiedono ormai più di un metodo per comunicare al motore l’esistenza di URL nuovi, pertanto la velocità di scoperta dei nuovi URL è influenzata da fin troppi fattori oltre a quello della sola importanza associata al sito.
Come regola generale, dunque, il fatto che il motore sia in grado di scoprire velocemente i nuovi URL generati dal sito non può essere considerato di per sé un indicatore di alcunché. Al contrario, se i nuovi URL di un sito non vengono scoperti dal motore entro un lasso di tempo ragionevole (es: 48 ore) allora questo può effettivamente essere considerato un indicatore del fatto che il sito non è considerato particolarmente importante da Google.
Si noti che “scoperta” viene usato nel contesto del crawling nell’accezione “quando lo spider effettua il primo accesso alla risorsa” e non quando la risorsa viene indicizzata.
Aggiornamenti
Alcuni URL vengono ri-spiderizzati più frequentemente di altri, perché il motore di ricerca ritiene importante individuare aggiornamenti ai contenuti.
La ri-spiderizzazione è un fenomeno estremamente comune e, anche nei siti web grandi, si osserva dai log che diverse risorse considerate importanti vengono richieste ripetutamente in misura maggiore delle risorse considerate secondarie.
La ri-spiderizzazione è anche un fenomeno particolarmente importante per i blog ed i siti di news, a maggior ragione se tali siti sono presenti nell’indice di Google News. Ma il crawling effettuato da Google News segue criteri molto diversi dal crawling del web e quindi non approfondirò questo punto per non andare fuori tema.
Per tutti quei contenuti che non sono associati a feed o news, la frequenza di ri-spiderizzazione è correlata principalmente a quattro fattori: 1) PageRank, 2) quanto frequentemente vengono aggiornati i contenuti della pagina, 3) quanto del contenuto viene cambiato e 4) il parametro changefreq nella sitemap XML.
Profondità fisica e profondità logica
Il concetto che sto per esporre è piuttosto importante, perché può aiutare a comprendere come mai Googlebot è indotto a (ri)chiedere alcune risorse invece che altre.
Poniamo il caso che esista un sito che riceva backlink esclusivamente sulla propria home page. In tal caso la home page sarà l’unica pagina a ricevere PageRank dall’esterno e di conseguenza la pagina dalla quale il flusso del PageRank partirà per essere distribuito in modo più o meno indiretto a tutte le altre risorse del sito.
In questo caso, del tutto teorico, la profondità di un URL può essere approssimata in modo grezzo col numero di click minimo che dalla home page conducono alla risorsa con quell’URL.
Se immaginate tale sito come una struttura gerarchica simmetrica, ogni livello della gerarchia ospiterà risorse più profonde di quelle del livello gerarchico precedente. E voi direte: “Grazie al piffero, gerarchia significa esattamente quello.”.
Sul web tuttavia la realtà è molto diversa perché pressoché tutti i siti ricevono backlink sia alla home page sia a risorse più interne. Di conseguenza la home page non può più essere considerata l’unica pagina dalla quale il PageRank esterno viene ridistribuito internamente.
Detto in altre parole, non esiste più una singola pagina principale del sito ma ne esistono molteplici, in quanto gli utenti possono approdare al sito iniziando anche da pagine che non siano l’home page.
In questo caso è giusto percepire la profondità di un URL in modo diverso. Sebbene la sua profondità fisica corrisponda sempre al numero minimo di click che separano l’URL dalla home page, la sua profondità logica dipende anche da quanto l’URL è distante da tutte le risorse del sito che ricevono backlink dall’esterno.
Per esempio, se una pagina indice di categoria riceve molti backlink dall’esterno, allora essa stessa e le risorse che essa linka avranno una profondità logica inferiore a quella fisica, come esemplificato nel grafico che segue.
Il grafico mostra in alto un esempio di gerarchia con indici di profondità (i numeri tra parentesi quadre) strettamente fisici ed in basso un esempio di gerarchia con indici di profondità logica, influenzati dai backlink ricevuti dalle risorse interne (i valori numerici sono puramente indicativi).
Perché è importante comprendere la differenza tra profondità fisica e logica? E’ importante perché solo tenendo conto di come il sito riceve backlink dall’esterno è possibile percepire correttamente se una specifica sezione del sito sta ricevendo la giusta attenzione da parte di Googlebot.
Una corretta comprensione delle profondità logiche, inoltre, è utile per capire se le sezioni con contenuti particolarmente profondi possono essere rese “meno profonde” dal punto di vista logico aumentando i link che puntano ad esse, sia i link provenienti da altri siti sia i link provenienti dalle altre risorse dello stesso sito (e questo è un punto in cui la progettazione dell’architettura dell’informazione può influire sulla distribuzione dell’importanza tra le risorse).
I furbastri tra di voi avranno intuito che la “profondità logica” non è altro che un altro modo di concepire la distribuzione del PageRank tra le risorse del sito. Se ho voluto parlare di profondità e non di PageRank è perché alla parola “PageRank” è facile che la memoria vada alla fuorviante e striminzita barretta verde, che così poca informazione fornisce a webmaster e SEO. A mio parere è più utile imparare a stimare quanto una risorsa sia “vicina alla cima” sulla base dei link interni che riceve dal sito stesso e dei link esterni che riceve dal web.
La grossa raccomandazione che è necessario fare in chiusura di questa sezione del post è quella di non dimenticare mai che tutte le considerazioni appena esposte si riferiscono a quanto gli spider sono indotti a perlustrare in base ai link interni ed esterni del sito, ma che bisogna sempre tenere conto del fatto che gli spider possono sfruttare altri canali preferenziali di individuazione e accesso alle risorse, come sono per esempio le sitemap XML o i feed.
Hidden web e spazi infiniti
Ci sono casi in cui Googlebot decide di andare a fondo molto più di quanto il PageRank delle risorse giustificherebbe.
Il fenomeno avviene quando lo spider tenta di effettuare il crawling di FORM di tipo GET oppure quanto tenta di indovinare URL possibilmente usati sul sito ma non esplicitamente linkati (URL guessing) oppure quando un sito web crea inconsapevolmente quelli che Piersante ha battezzato “spazi infiniti“.
Un esempio tipico di spazi infiniti viene a crearsi quando il widget di un calendario usa dei normali link per navigare il calendario stesso, col risultato di arrivare indirettamente a linkare un infinito (o estremamente alto) numero di anni e date future, ciascuna delle quali corrisponde ad una risorsa HTML indicizzabile.
Queste tipologie di crawling e le loro profondità non possono essere correlate ad alcun segnale sull’importanza assegnata dal motore alle risorse e vanno pertanto considerate “attività speciali” di crawling che seguono criteri diversi da quelli legati all’importanza delle risorse scoperte.
Nell’esempio di analisi che mostrerò nell’ultima parte di questo articolo darò evidenza del fatto che questo tipo particolare di crawling non è incentivato nemmeno dalla qualità dei contenuti trovati sulle risorse richieste.
Full recrawl
Simile al fenomeno che in passato veniva chiamato “deep crawl” (e che adesso probabilmente non esiste più come concetto) il full recrawl avviene quando il motore di ricerca decide di svolgere un crawl quanto più completo del sito stesso. Tale decisione è a volte conseguente ad un cambiamento radicale dei contenuti del sito e delle sue URL.
Visto che il full crawl è un comportamento temporaneo e a volte una conseguenza di uno specifico fenomeno avvenuto sul sito, non è corretto considerarlo correlato all’importanza che il motore di ricerca ha assegnato al sito stesso.
Dalla teoria alla pratica
Imparare a capire dai comportamenti di Googlebot in che modo il sito è considerato dal motore di ricerca è, come detto, un obiettivo raggiungile solo facendo pratica con l’analisi dei log, tuttavia ho pensato di mostrarvi un esempio pratico di analisi, non perché esso sia un esempio di applicazione di tutte le nozioni sopra espresse, ma perché può essere considerato un piccolo tassello di quanto si può osservare ravanando nei file di log del server.
Informazioni sul sito analizzato
Il sito da analizzare ospitava, tra le altre cose, contenuti classificati per zone geografiche (città) ed avevo un interesse a comprendere quali sezioni geografiche ricevevano maggiore attenzione da parte dello spider, sopratutto in funzione degli obiettivi di business dell’azienda, che desiderava puntare più su alcune specifiche zone.
Una prima perlustrazione con Xenu Link Sleuth aveva fatto emergere una criticità di “spazi infiniti”; il crawling del sito era stato interrotto una volta preso atto del problema ed è dunque nata la volontà di capire quanto il fenomeno stava interessando Googlebot e quanto il sito stava sprecando preziosa banda.
Obiettivi dell’analisi
I due obiettivi che mi sono dato sono stati quello di evidenziare eventuali anomalie nel crawling e quello di determinare quali sezioni del sito da analizzare ricevevano maggiore attenzione dagli spider.
Strumenti utilizzati
Nel corso del tempo ho modificato più volte il tipo di strumenti usati per l’analisi dei log.
A volte mi sono affidato a soluzioni software dedicate in modo specifico a questa attività, altre volte ho preferito adottare soluzioni più artigianali, sopratutto quando avevo bisogno di estrarre informazioni particolari.
In passato, per esempio, mi sono affidato a Deep Log Analyzer per creare dei report custom basati su query SQL, senonché il software diventava molto lento nel momento in cui c’era da analizzare una quantità di log corposa.
Più recentemente, ho scoperto un piccolo e semplice software per filtrare velocemente i log e per dare loro delle veloci occhiate, si chiama Apache Logs Viewer (ma gestisce anche i log dei web server Microsoft).
Nel caso dell’analisi che vi sto per illustrare mi sono tuttavia affidato a semplici metodologie custom basate su grep (e l’inusabile ma potente PowerGrep) ed Excel. Sono ricorso anche all’aiuto saltuario di UltraEdit per visualizzare i dati grezzi.
Approccio seguito
E’ stato preso in considerazione un periodo temporale di sette giorni, distante da campagne di marketing svolte dall’azienda proprietaria del sito e giudicati sufficienti per estrarre un comportamento abituale di Googlebot.
Dai file di log sono state estratte le sole righe relative a Googlebot, circa ventiduemila, che sono state modificate con PowerGrep attraverso una regex per separare con TAB i vari campi di cui la riga di log si componeva e successivamente importate in Excel.
Su Excel è stata aggiunta una colonna destinata ad ospitare il nome della directory che conteneva la risorsa richiesta dallo spider e successivamente è stato creato un semplice grafico pivot che mettesse in risalto le directory più oggetto delle perlustrazioni dello spider.
Nello screenshot che segue potete vedere il grafico a torta che mette in evidenza le proporzioni tra le varie directory. I nomi reali delle directory sono stati cambiati per proteggere gli innocenti, ho lasciato reali solo i nomi delle regioni, giusto per amor patrio.
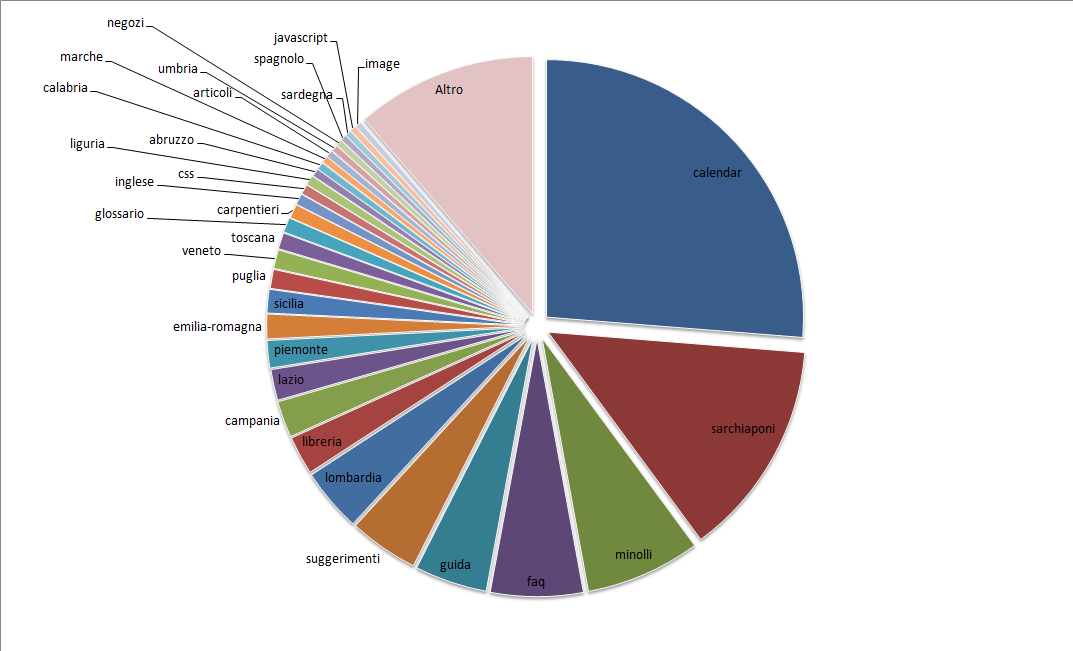
Osservazioni
Come si può notare, oltre un quarto delle richieste di Googlebot sono dedicate alla cartella che ospita la risorsa che genera gli “spazi infiniti”, nella fattispecie si trattava di un widget “calendario” che induceva lo spider a richiedere seguire link che puntavano ad anni futuri, fino a generare pagine riferite all’anno 2041.
L’aspetto interessante di questo comportamento di Googlebot è che le risorse in questione consistevano in pagine vuote, bianche come la neve e che includevano giusto quei link che spingevano lo spider ad andare sempre più in profondità.
Questo appena descritto è un tipico esempio di crawling non associabile alla distribuzione del PageRank. Oltre certi livelli di profondità, la quantità di PageRank associata alle risorse è quasi zero e non sufficiente a giustificare un ulteriore interessamento da parte dello spider a proseguire oltre.
Il fatto che i contenuti trovati ad ogni nuovo approfondimento fossero nulli fa anche pensare che l’obiettivo dello spider di individuare una quantità maggiore di risorse fosse talmente prioritario da non tener conto della qualità dei contenuti già trovati.
E’ questa osservazione sufficiente a far concludere che Googlebot non tiene conto della qualità delle risorse per decidere se andare a fondo o meno?
No. Come detto, infatti, esistono delle attività speciali dello spider che prevedono che esso vada più a fondo possibile, senza tener conto di qualità o importanza. Ma va sempre ricordato che la normale attività di crawling tiene sempre conto del PageRank delle risorse e quindi non ci si deve attendere per le normali risorse del sito lo stesso trattamento ingordo che viene concesso a quelle risorse superprofonde oggetto di crawling particolari.
In altre parole, lo spider è unico ma i task che gli vengono assegnati possono essere molteplici, ed uno di questi prevede di andare a fondo ad ogni costo al presentarsi di particolari scenari, come un FORM da “compilare” o un calendario da sfogliare (e qui vengono in mente audaci paralleli con camionisti e ragazze svestite che non farò per pudore e tatto).
Preso atto che oltre un quarto delle richieste riguardava interrogazioni a risorse inutili, va da sé che una correzione di questo problema potrà garantire un po’ di banda in più da sfruttare per lo scaricamento di risorse più strategiche.
Un’altra osservazione che emerge dal grafico è che la directory “carpentieri” è piuttosto snobbata dallo spider, pur rappresentando una tipologia di risorse sulle quali il cliente desiderava puntare. Sarà dunque necessario comprendere perché questo avviene e se è il caso di invitare in qualche modo lo spider a prestare maggiore attenzione a quela sezione, per esempio lavorando sui contenuti di quelle pagine oppure sul linking interno. Anche la directory “negozi” è messa piuttosto male e meriterebbe più attenzione.
Un’ulteriore osservazione è relativa all’attenzione concessa da Googlebot alle zone geografiche: sembra che lo spider sia più interessato a quelle città che vedono una maggiore presenza di UGC (user generated contents) sulle relative risorse. Questa informazione è interessante, vale la pena di prendere un appunto e di fare delle comparazioni tra le città di cui lo spider è più ingordo, quelle per le quali riceve più traffico organico e quelle sulle quali il cliente vuole effettivamente puntare di più. Chissà che non emergano considerazioni e nuove idee su come valorizzare le città più strategiche agli occhi degli utenti e del motore di ricerca…
Il resto delle sezioni del sito, a cominciare da “sarchiaponi” e “minolli” è abbastanza compatibile con quella quantità di attenzione che il sottoscritto ritiene giusto associare ai vari contenuti, pertanto l’analisi serve anche a capire quali cose filano per il verso giusto.
Mettere le cose in prospettiva
Occhio: l’analisi dell’attenzione degli spider non serve a nulla se non tiene in considerazione anche gli altri, importantissimi, elementi che ho più volte accennato lungo l’articolo: la qualità del traffico che arriva dai motori, gli obiettivi dell’azienda e la visibilità nei risultati delle ricerche.
Fate dunque bene attenzione ad incastonare le analisi del comportamento di Googlebot in quel puzzle più grande che è il rapporto tra sito e motore, di cui i log possono essere solo un parziale indicatore.
Conclusioni
Volevo anche aggiungere una nota sui dati che possono essere estratti da Google Wemaster Tools, in particolare quelli relativi alle risorse indicizzate ed esplicitamente “snobbate” dal motore di ricerca. Nel momento in cui scrivo questo articolo (gennaio 2013) GWT specifica quante risorse vengono ignorate, ovvero la quantità di risorse “not selected”, ma non quali.
Quindi magari dare ogni tanto un’occhiata ai log del server e alla robaccia che fate scaricare allo spider può essere un buon modo per capire la causa dei picchi della famigerata linea delle risorse che il motore preferisce ignorare. Evitare gli sprechi porta sempre benefici.
P.S.
Pensavo che sarebbe interessante parlare di argomenti simili in qualche evento. Giusto per dire.
Post molto interessante, forse nel mio caso capita a proposito… io non ho mai fatto uso dei log e statistiche lato server, ma finora mi sono servito solo di GTW
Ho notato qualcosa di strano, in un sito web dove mi risultano ben = 24.961 URL mai sottoposti a scansione, secondo Google.
Il sito web online da quasi 1 anno, ancora in costruzione, tutto in HTML statico, non ha calendari, nè form, nè database, nè CMS installati di nessun tipo.
Al momento avrà 50 pagine online, tutte indicizzate, ma GWT dice che quasi 25.000 non sono mai sottoposte a scansione…
http://www.seowebmaster.it/indicizzazione.png
Non sò come spiegare tutto ciò, ho ipotizzato che Googlebot abbia accesso a queste 25.000 pagine tramite Internet Archive, il dominio infatti nel 2007 era online.
Quindi è possibile che Googlebot continui a richiedere queste pagine archiviate e non più disponibili da 5 anni…
Tu Enrico come risolveresti il problema? Sempre ammesso che sia un problema!
@seowebmaster: premettendo che quelle non sono “pagine mai sottoposte a scansione” (è un errore di traduzione) ma “totale delle pagine finora scansionate”, la prima cosa che farei è acquisire informazioni su quanto è successo nella data del picco di richieste, per esempio dando un’occhiata ai log di quei giorni.
Da quel poco che si evince dal grafico, si è trattato comunque di un picco di richieste isolato e il fenomeno non è più avvenuto da allora (quella linea non mostra le richieste giornaliere ma è cumulativa, quindi non può mostrare discese).
Cause ed eventuali criticità non possono essere valutate con certezza se prima non si indaga su quali URL sono stati richiesti da Googlebot. Essendo comunque stato un fenomeno di quasi un anno fa, indagherei per scrupolo ma senza eccessive preoccupazioni.
Ciao Enrico, articolo molto interessante. Ho due domande: analizzando un po’ di log, non ho mai trovato risposte al Googlebot con status code 304 Not Modified.Tu ne hai mai trovati?
Immagino che lo spider non abbia una cache come un tradizionale browser e quindi,suppongo che l’unico modo che lo spider ha per verificare se una risorsa è cambiata, è scaricarla e confrontarla con la precedente versione memorizzata.
Visto che scrivi che la banda dedicata ad ogni sito è limitata ( io l’ho sempre ragionata in termini di tempo piuttosto che di kb) è evidente che i contenuti nuovi, debbano essere linkati nel migliore dei modi, sennò si rischia che il bot si “scarichi” sempre le stesse risorse.
Secondo te eliminare provvisoriamente (da leggersi come “per un periodo sufficientemente lungo”) la sitemap può essere utile per identificare i problemi di architettura informativa del sito? Se da una parte la sitemap risolve i problemi, dall’altra parte credo anche ne possa nascondere altri altrettanto importante (=linking interno inadeguato o errato)
@andreacardinali: Ciao Andrea. Sì, i 304 sono comuni se il server/CMS è configurato correttamente. Googlebot gestisce i response header Last-Modified ed invia gli header If-Modified-Since da diversi anni, è anomalo che tu non abbia mai trovato un 304.
Lo spider fa riferimento ad una cache interna, quindi il meccanismo del “Not Modified” esiste ed è funzionante. Ci sono casi in cui Googlebot potrebbe voler comunque scaricare la risorsa, ma come regola generale invia gli If-Modified-Since per risparmiare banda.
Il rispetto degli header per la gestione della cache non è pieno. Più volte ho osservato lo spider chiedere risorse che erano ben lontane dall’essere scadute, come se lo spider volesse comunque testare di persona l’eventuale modifica della risorsa. Non ho mai approfondito la questione e quindi non ti so dire in quali casi Googlebot decide di fregarsene ed in quali casi rispetta le direttive.
Prima della nascita delle sitemap XML, osservare il comportamento di Googlebot nei log era un buon modo per capire quanto lo spider desiderava andare a fondo in funzione del linking interno e lo è ancora oggi per i siti che una sitemap non ce l’hanno. Non mi sento di consigliare di eliminare temporaneamente la sitemap XML come suggerimento generico, perché per alcuni siti web la sitemap rimane uno strumento importante sul quale eviterei di svolgere esperienti così radicali.
Tuttavia se si è disposti ad accettare gli eventuali problemi di indicizzazione che ne potrebbero derivare, l’eliminazione provvisoria rimane sicuramente un modo per togliere complessità al processo decisionale di Google e per osservare quanto il sito induce “per propria natura” lo spider ad andare a fondo.
Aggiungo al commento precedente: sai se Googlebot rispetta gli header Expire,Cache-Control e Vary ?
Il post è molto interessante, apre sicuramente scenari di approfondimento che non sono quasi mai affrontati, l’ultima volta che se ne è parlato mi pare ne parlasti tu a un convegno di Madri, sbaglio?
@stefano bortuzzo: Confesso di non ricordare se ne parlai da Madri. 🙂 Lo studio dei log rimane comunque utile per tante altre necessità; proprio in questi giorni li ho sfruttati per capire il perché di alcuni errori di attribuzione della fonte di provenienza dei visitatori di un sito.
Ciao Enrico, anch’io ho una domanda per te: noto che i siti web verticali (diciamo aziendali) hanno spesso un recaching più frequente per le homepage che per i contenuti interni, mentre per i blog si verifica il contrario. Dipende dal fatto che spesso i siti web del primo tipo hanno più backlink verso la homepage, mentre nei blog tale potere e redistribuito per i singoli post?
@Francesco: Ciao, sì, nella pratica è proprio come hai detto. Come accennavo nell’articolo in un paio di punti, le logiche che stanno dietro i siti con feed sono un po’ diverse, un po’ perché oltre al canale classico dei backlink esiste anche quello parallelo dei feed e dei ping, un po’ perché la distribuzione dell’importanza tra le risorse è un po’ più omogenea rispetto al modello strettamente gerarchico dei siti “classici” ed un po’ perché articoli e news hanno una buona probabilità di essere linkati direttamente da siti esterni.
Sommando tutto, gli spider sono quindi incentivati a focalizzare la propria attezione sugli articoli. Se poi il blog è su Google News, il fenomeno è ancora più evidente, sopratutto perché le notizie nuove vengono visitate più volte dallo spider delle news durante i primi due giorni di vita dell’articolo.
Ottimo post Enrico!
Però non mi dovevi mischiare Walter Chiari (sarchiaponi) con Troisi (minolli) solo per proteggere degli innocenti.
Specialmente se gli innocenti sono quelli che penso io… 😉
@Gianpaolo: volevo fare un omaggio a due grandi artisti e ci è scappata la doppia citazione. 🙂 Comunque no, l’articolo fa riferimento ad innocenti veri, che non conosci. 🙂
Con il suo permesso dottò mi salvo il pdf e archivio in cloud questo pezzo di know-how. Content is the king è la tua nuova roadmap? Complimenti 🙂
@EVE Milano: diciamo che ho imparato a trarre vantaggi dall’essere prolisso. 🙂 Grazie dei complimenti!
Ciao Enrico
hai mai notato una correlazione tra comportamento strano dello spider e penalizzazione del sito?
Io si, ma non so se è un caso è se può essere un sintomo di penalizzazione
@lucaime: Ciao Luca, non ho aggiunto nulla all’articolo sul punto delle penalizzazioni perché recentemente non mi è capitato di analizzare i log di un sito penalizzato (con probabilità o in modo dichiarato da Google).
L’unica esperienza in tal senso risale a diversi anni fa e non ne ho fatto cenno nel post perché lo considero un episodio troppo vecchio per poter essere riportato come certezza; l’accenno comunque di seguito.
Si trattava di un fenomeno che vedeva da un lato una riduzione delle attività di crawling globali e dall’altro il frequente check di specifiche risorse, contenenti le caratteristiche che presumibilmente avevano prodotto la penalizzazione. Ricordo la congettura che feci all’epoca: il task di controllo era probabilmente legato all’obiettivo di Google di accorgersi di un’eventuale “bonifica” della pagina da parte del proprietario del sito.
Non ricordo altre esperienze in merito.
Una sola parola: esaustivo! Ed è un aggettivo che può essere usato per pochissimi bloggers, complimenti 😀
Un appunto sulla parte della scoperta delle URL. Io averi aggiunto anche il fetching che l’utente può richiedere tramite il GWT.
Per il resto, tanto di cappello come sempre.
@Andrea Moro: Hai ragione, Andrea, non solo non ho fatto accenno al fetch attraverso GWT ma anche a molti degli elementi di URL discovery citati nel post e nei commenti della Mappa dell’indicizzazione, a suo tempo compilata col contributo di tanti SEO.
La ragione della mancata citazione del fetch via GWT, tuttavia, è che l’obiettivo dell’articolo è quello di dare una spiegazione dei vari comportamenti “naturali” di Googlebot, perché solo questi possono essere indicatori di quanto il motore è interessato al sito. Gli accessi che nascono da un’esplicita richiesta di fetch da parte del gestore del sito sono invece privi di informazioni utili: te li ritrovi nei log semplicemente perché li hai chiesti.
Decisamente un’ottima riflessione Enrico, completa e puntuale sugli aspetti più tecnici.
Un’articolo che dovrebbe essere letto alla prima lezione di un aspirante SEO Master!! Complimenti 😉
Io ho notato la stessa cosa, pochi mesi fa. Un sito penalizzato ha subito una drastica diminuzione delle attività di crawling, non ho però notato il check frequente di specifiche risorse.
@Luca Bove: nel mio caso sui trattava di una penalizzazione algoritmica focalizzata su contenuti specifici del sito. Anche nel tuo?
Pingback: SEO in Italia: Gli Articoli Da Non Perdere Assolutamente
E’ possibile avere maggiori informazioni su come filtrare un file di log per estrapolare SOLO gli accessi di Googlebot? Io ho creato uno script in php che legge il file di log e ho filtrato le righe in base alla presenza o meno della parola “Googlebot” ma i dati che mi restituisce ho alcuni dubbi.
Ho trovato molto interessante la chiave interpretativa estremamente tecnica di alcune dinamiche della SEO. Su alcune considerazioni nutro dei dubbi, ma ripeto: un post davvero interessante.
Ciao, Gianni.
Ciao, ho trovato molto interessante l’articolo e ti propongo alcune (spero brevi!) considerazioni.
Anche se non mi occupo di seo, da tempo eseguo analisi sui siti, sui file di log in tempo reale ed in particolare sulle rappresentazioni dei grafi dei siti secondo diversi criteri quali la profondità fisica, logica (secondo criteri simili a quelli da te descritti ma con l’aggiunta di altri dati) in modo da vedere “a colpo d’occhio” che relazione c’è (se c’è) tra passaggi di google su una pagina/ramo, interesse degli utenti (tempo medio su pagina – fonte analytics), back link pesati etc. Rappresentare un sito in modo grafico si è rilevata la scelta vincente per individuare senza tanti calcoli delle relazioni e fare delle ipotesi. Se ci sarà occasione di approfondire, ben volentieri.
Tornando al tuo post, dai dati in mio possesso risulta che la semplice ricerca dell’agent di google non fornisce dati corretti: su decine di milioni di visite del bot di google, circa il 14% delle volte non è google! Lo scopri facilmente facendo il reverse dell’ip e se ottieni “alice-xxx” di sicuro non è google. Perché fingersi google? Ho un po’ di ipotesi ma per i miei scopi non è rilevante mentre è importante avere i dati puri (altrimenti ragiono su cosa?)
Per quanto riguarda l’utilizzo di Xenu, occorre fare attenzione ad alcune cose che possono complicare l’analisi: ad esempio, se nel sito analizzato ci sono dei link interni che sono poi ridiretti con 301 e dei link alla pagina reale, Xenu li considera come due pagine distinte ( ti segnalerà contenuto duplicato ) e ti complicherà la vita nel tracciare i percorsi. La stessa “cautela” occorre utilizzarla sui file di log.
Se può essere di interesse, posso postare un link con alcuni degli strumenti che abbiamo realizzato in questi anni che sono disponibili gratuitamente (un text browser, l’elenco degli ip sicuramente appartenenti a google ed un tool di analisi del sito): fanno parte di un progetto più ampio (ahime!, non ha finalità seo) che terminerà con la mappa “cognitiva” del sito da sovrapporre agli altri grafi di cui accennavo all’inizio. Ciao e buon lavoro!
Pingback: Come {fallire nel} trovare lavoro in aziende che fanno Seo
Pingback: 3 strumenti SEO avanzati per l'analisi del tuo sito web
Pingback: Come funziona Google (solo un antipasto...) - LowLevel’s blog