-
Questa opera di Enrico Altavilla è concessa in licenza sotto la Licenza Creative Commons Attribuzione - Non commerciale - Non opere derivate 3.0 Unported.
Incremento dei click sulle SERP: dal test al “Click Love”

Per chi mi segue da un po’, sa che il tipo di web analysis che mi piace di più è quello che prevede di sporcarsi con po’ le mani con test e calcoli.
Questo articolo descrive come ho svolto un test per determinare se una piccola modifica al testo di un tag TITLE avrebbe prodotto un CTR maggiore sulle SERP di Google.
Come spesso capita, tuttavia, “l’appetito vien mangiando” e oltre a determinare l’esito del test sulla base dei KPI definiti, lungo il cammino mi è venuta un’idea per definire un KPI diverso dal CTR, che potrà essere sfruttato in test futuri.
Vi do dunque visibilità dell’intero processo che ho seguito, dall’idea all’esecuzione, alle considerazioni che mi hanno spinto a tirar fuori dal cappello anche qualcosa di nuovo.
Ne approfitto per ringraziare il cliente che mi ha dato il permesso di divulgare i risultati del test, opportunamente anonimizzati.
Obiettivi del test
Avendo a disposizione una risorsa con una solida visibilità per “money query” abbastanza popolari e che da tutti i check di ranking appare saldamente ancorata alle stesse posizioni da molto tempo, ho pensato di svolgere un test per vedere se il CTR sulle SERP sarebbe aumentato.
L’idea di base era quella di aggiungere al testo del tag TITLE della risorsa un semplice aggettivo che avrebbe potuto motivare maggiormente gli utenti a cliccare sul risultato.
Oltre a misurare eventuali benefici sul CTR, esistevano due ulteriori ragioni per effettuare un test su una specifica risorsa:
- comprendere se la modifica al testo del titolo avrebbe potuto influenzare negativamente la visibilità della risorsa, un dubbio che andava necessariamente dissipato prima di estendere eventualmente la tecnica ad altre pagine del sito web
- sposare pienamente quel sano approccio che prevede che le decisioni debbano essere supportate dai dati, quando possibile, invece che indotte da opinioni, congetture ed ipotesi non confermate.
La modifica al titolo
Tipo di modifica
La risorsa oggetto del test ospitava informazioni su prodotti. La modifica al testo del titolo è consistita nell’informare l’utente del motore, attraverso l’inserimento di un semplice aggettivo, della freschezza di tali informazioni.
Semantica
Grande attenzione è stata posta nel non stravolgere il senso del titolo a seguito della sua modifica. Il titolo è stato dunque mantenuto sostanzialmente identico, in modo che il messaggio veicolato al lettore rimanesse lo stesso.
Mantenimento del target
Esisteva l’obiettivo di non produrre grandi cambiamenti all’insieme di query per le quali la risorsa era visibile. L’aggettivo aggiunto al titolo, quindi, è stato preferito ad altri anche perché non era tipico delle query degli utenti interessati a quel genere di risorse.
Obiettivi di comunicazione
In comparazione con l’aggettivo che è stato poi utilizzato nel test, esistevano sicuramente altri aggettivi che avrebbero potuto attrarre maggiormente il click degli utenti. Alcuni aggettivi, tuttavia, avrebbero potuto essere percepiti come leggermente fuorvianti o meno attinenti dai visitatori della risorsa. Il test pertanto ha tenuto conto degli obiettivi di comunicazione ed il cliente ha scelto un aggettivo che non avrebbe potuto generare alcuna perplessità o ambiguità.
KPI, misurazioni e condizioni
Per determinare se il titolo modificato avrebbe portato più risultati di quello originario, è stato necessario definire con chiarezza un KPI ed una serie di condizioni che avrebbero reso il test valido solo se le stesse fossero state rispettate.
La definizione dei KPI è una delle fasi più strategiche di un test, perché non è sufficiente scegliere un indicatore ma è necessario anche specificare in che modo esso va calcolato e quali strumenti usare per misurare esso o altri dati che concorrono a determinarlo. Più il processo di definizione dei KPI è rigoroso, più i risultati del test possono essere considerati attendibili.
Esistono inoltre diversi altri vantaggi per definire i KPI in modo rigoroso: innanzitutto una procedura chiara e dettagliata del loro calcolo permette di rendere il processo riproducibile in modo corretto anche in occasioni future, in secondo luogo la riproducibilità consentirà ad altre persone di cimentarsi nelle stesse misurazioni ottenendo risultati comparabili con quelli di test precedenti.
KPI
Il KPI scelto per misurare l’esito del testo è stato il CTR sulle SERP di Google riferito alla risorsa di cui sarebbe stato modificato il titolo. Il valore di CTR sarebbe stato calcolato dividendo i click ricevuti per le impression effettuate da Google. Lo strumento attraverso il quale estrarre i dati di click e impression sarebbe stato Google Webmaster Tools, che fornisce esplicitamente tali informazioni. L’acquisizione del dato sarebbe avvenuta attraverso il pannello di Google Analytics, sul quale è possibile importare i dati di GWT.
La comparazione da fare per determinare l’esito del test sarebbe stata quella tra il CTR registrato sui ventuno giorni che precedono il cambio del testo del titolo sulla SERP ed il CTR registrato sui ventuno giorni che seguono il cambio del testo del titolo sulla SERP. Pertanto:
[latex]\text{CTR su un periodo} = \frac{\text{Click registrati sul periodo}}{\text{Impression registrate sul periodo}}[/latex]
[latex]\text{KPI} = \text{CTR dei 21 giorni precedenti alla modifica} – \text{CTR dei 21 giorni successivi alla modifica}[/latex]
Misurazioni
L’acquisizione dei dati necessari al calcolo del KPI avrebbe previsto l’estrazione da Google Analytics delle informazioni su impression e click di ciascuno dei giorni interessati ai periodi su cui sarebbero stati effettuati i calcoli.
Queste informazioni sarebbero state acquisite da GA nel seguente modo:
- Accedendo alla sezione Traffic Sources > Search Engine Optimization > Landing Pages
- Aggiungendo all’elenco un filtro che mostrasse esclusivamente la risorsa oggetto del test
- Facendo mostrare sul grafico sia impression sia click
- Esportando i dati attraverso la voce Export > Excel
Condizioni
Affinché il test possa essere considerato valido, è necessario che le seguenti condizioni vengano soddisfatte:
- Durante il periodo monitorato dal test, la posizione media della risorsa non deve cambiare in maniera consistente. La tolleranza massima accettata è di 0.2 posizioni di differenza tra la posizione media registrata sulle venti giornate precedenti la modifica e la posizione media registrata sulle venti giornate successive alla modifica.
- Durante il periodo monitorato dal test, lo snippet mostrato da Google dopo il titolo non deve subire modifiche per le top 10 query che generano più impression.
- Durante il periodo monitorato dal test, la classificazione delle query (es: informative, transazionali, ecc.) per le quali la risorsa viene proposta da Google non deve cambiare a seguito di fenomeni di mercato o stagionali. Per esempio, se una parola tipicamente presente nelle query diventasse il brand di una nuova azienda che si propone sul mercato, questo evento potrebbe modificare la classificazione di alcune delle query.
Se ci fate caso, tutte le condizioni sono state imposte per garantire che durante il periodo del test non subentrino fenomeni che potrebbero cambiare il CTR della risorsa monitorata.
In altre parole, comparare il CTR di due diversi periodi ha senso solo se durante il test lo scenario delle SERP rimane in più possibile stabile.
Il test
Sulla SERP, il testo del titolo della risorsa è cambiato in data 7 gennaio 2013.
La data era un po’ infausta, perché con l’epifania si chiude il periodo di festività e temevo che vi potessero essere differenze di comportamento degli utenti tra il periodo delle festività e quello di ritorno al lavoro. Come darò evidenza nella sezione “Fugare i dubbi”, non sono emerse evidenze a sostegno del mio timore.
A fine gennaio 2013, il test è stato chiuso. Sono state svolte delle analisi per accertarsi che le condizioni necessarie fossero state rispettate e prima di mettermi a calcolare il valore del KPI, ho iniziato a dare un’occhiata non-scientifica al CTR su Google Analytics, perché ero curioso di vedere se c’erano evidenze di una miglioria già “ad occhio nudo”.
Prime evidenze
Per scorgere eventuali differenze nel CTR in modo visuale, ho pensato di usare la visualizzazione animata di Google Analytics, partendo dal primo dicembre 2012 e facendo avanzare l’animazione fino alla fine di gennaio 2013. Ho ritenuto che il tipo di animazione più chiaro fosse quello con una barra verticale.
Che cosa osservare nel video che segue: il CTR della pagina ha oscillato attorno al 20% per tutto il periodo precedente la modifica del titolo sulla SERP. Dal momento in cui la modifica è stata apportata (periodo evidenziato in verde) il CTR del 20% è diventato invece la base minima ed il valore non è più sceso sotto quella soglia.
Già da queste prime osservazioni non emergeva un incremento consistente del CTR però sembrava evidente una miglioria, che il calcolo del KPI ha successivamente confermato.
Calcolo del KPI
Una volta soddisfatte in modo non scientifico le mie curiosità estemporanee, ho calcolato il KPI secondo le modalità e le formule stabilite a monte.
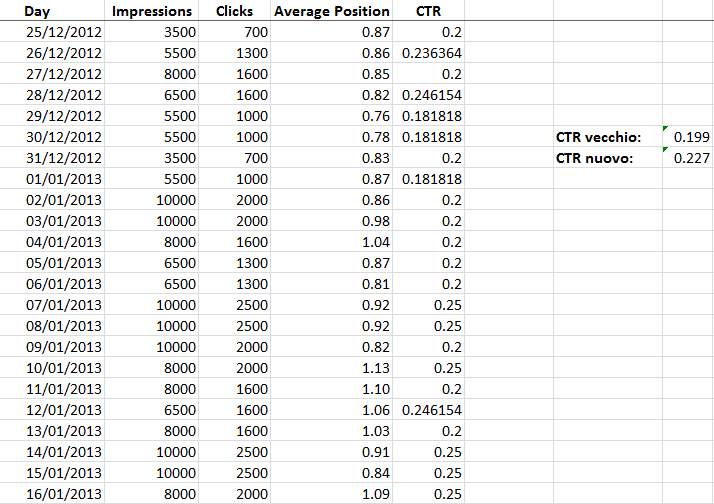
Da GA sono stati scaricati i dati di click e impression per la specifica risorsa oggetto del test ed è stato calcolato il CTR via Excel. Voglio sottolineare che non è stato preso il CTR comunicato da GWT/GA ma che esso è stato calcolato facendo il rapporto tra click e impression.
Una volta calcolato il CTR per ciascuna giornata, sono state calcolate le medie del CTR del periodo precedente alla modifica dello snippet e il periodo successivo alla modifica dello snippet.
Comparando il CTR medio dei due periodi è stato confermato anche matematicamente l’evidenza che emergeva dalla semplice osservazione dell’animazione del grafico del CTR: il valore risultava leggermente aumentato dal 19.9% al 22.7%.
Fugare i dubbi
C’era un ulteriore dubbio da fugare riguardo l’attendibilità del test: accertarsi che gli incrementi di CTR registrati nel secondo periodo non fossero imputabili ad una fisiologica variazione stagionale delle abitudini degli utenti.
Ho allora preso in esame un piccolo insieme di query che restituivano risultati diversi da quello oggetto del test, ma comparabili per tipologia. Per questi risultati lo snippet sulla SERP era rimasto invariato e una comparazione effettuata sugli stessi due periodi oggetto del test non ha mostrato variazioni di CTR (in positivo o negativo) significative quanto quella osservata sulla risorsa oggetto della modifica del testo del titolo.
Questa valutazione è tipica del test che fanno uso di un campione di controllo. Sarebbe stato meglio definire nel dettaglio le modalità di uso del campione di controllo prima dell’esecuzione del test, tuttavia in questo specifico caso ho dovuto ripiegare su un controllo post-test.
Esito del test
Il calcolo del KPI non dà spazio a dubbi e le condizioni inizialmente definite affinché il test potesse essere considerato valido sono state pienamente rispettate. Di conseguenza il test ha dimostrato che la lieve modifica al titolo della risorsa ha comportato un lieve incremento del CTR sulla stessa.
Esistevano quindi le condizioni per suggerire al cliente la modifica del titolo di altre risorse strategiche del sito, seguendo gli stessi criteri adottati per la risorsa oggetto del test.
E dunque test valido, risultato positivo, tecnica scalabile sul resto del sito, tutti contenti e bella lì.
Si può fare di più
Chiuso il test per il cliente, ho deciso di impiegare del tempo personale per ragionare sul KPI scelto, basato sul CTR della risorsa.
Non c’è dubbio che per voler misurare la capacità di una risorsa di attrarre dalla SERP il click dell’utente, il CTR è sicuramente l’indice che per primo viene in mente come strumento per misurare l’esito dell’attività.
Va però evidenziato che, per quanto sia una discreta base di partenza, il CTR è facilmente soggetto a fenomeni che inficiano test di questo tipo. Se la risorsa avesse cambiato posizione media in modo deciso durante i giorni di monitoraggio, il CTR sarebbe probabilmente cambiato in modo pesante, in quanto i click sulle risorse alle posizione superiori sono generalmente maggiori rispetto ai click sulle risorse alle posizioni inferiori.
Per esempio, una discesa della risorsa in SERP avrebbe prodotto un CTR minore e a quel punto non sarebbe stato possibile comprendere se e quanto la modifica al titolo avesse indotto gli utenti a cliccare di più o di meno. Allo stesso modo, una salita della risorsa nelle SERP avrebbe prodotto un CTR maggiore, da attribuire forse più al cambio di posizione che alla modifica del testo del titolo.
La scelta del CTR come KPI per un test simile rende dunque la validità del test stesso troppo facilmente vittima di fenomeni di cambio di posizione: se la posizione media subisce variazioni consistenti il test sarebbe invalido e da gettare via.
Nello specifico caso del test oggetto dell’articolo, ci si era volutamente focalizzati su una risorsa che da tempo mostrava posizioni consolidate e poco soggette ai naturali movimenti della SERP ma, nonostante l’esito positivo, al sottoscritto era rimasta la curiosità di individuare un KPI più solido, che mantenesse la propria validità prescindendo da eventuali cambi di posizione della risorsa.
Per essere più espliciti: volevo trovare un indicatore di quanto una risorsa in SERP fosse in grado di attrarre i click degli utenti in funzione del proprio “appeal”, a prescindere dalla sua posizione o dai cambiamenti di posizione. Se volete, consideratelo un indice di “intrinseca figosità”.
Siccome l’espressione “indicatore di quanto una risorsa in SERP fosse in grado di attrarre i click degli utenti in funzione del proprio appeal” era un po’ lunga, ho pensato per semplicità di chiamare questo indicatore “Click Love“. Adesso vi spiego come ci sono arrivato e come usarlo.
Click Love: prime prove
Il primo approccio per individuare una formula ragionevole per calcolare il Click Love è stato quello di partire dalla consapevolezza che ciò che appare in posizioni superiori è in media più cliccato di ciò che appare in posizioni inferiori.
Esistono eccezioni a questa regola, per esempio è stato notato che in diversi contesti il risultato che sta in prima posizione della seconda pagina può avere un CTR maggiore rispetto all’ultimo risultato della prima pagina. Per semplicità di analisi, tuttavia, restringerò il campo di studio alla sola prima pagina delle SERP.
Tenendo conto di questo naturale fenomeno di distribuzione dei click sulla SERP, è possibile fare delle prime considerazioni su come attribuire un Click Love ad una risorsa in SERP. Per esempio, un CTR alto misurato su una risorsa in prima posizione può essere plausibile ma lo stesso CTR misurato su una risorsa in settima posizione evidenzierebbe una particolare capacità di quella risorsa ad attrarre i click nonostante la posizione bassa.
Nella seguente tabella mi sono limitato a fare delle considerazioni sul significato di un CTR in base alla posizione della risorsa su cui è stato osservato, a parità di risorsa e query ed esagerando volutamente i valori per facilitare la comprensione della logica di fondo:
| CTR | Posizione media | Valutazione risultato |
|---|---|---|
| 30% | 1 | CTR plausibile per una prima posizione. Nulla di speciale. |
| 30% | 3 | CTR molto alto per una terza posizione. La risorsa è stata in grado di attrarre click ben oltre a quanto la semplice posizione giustificherebbe. |
| 30% | 6 | CTR estremamente improbabile per una risorsa in sesta posizione. Qualunque cosa quella risorsa stia facendo per meritare click, lo sta facendo incredibilmente bene! |
Sulla base delle suddette considerazioni è possibile abbozzare già una prima formula per il calcolo del Click Love. So che, a parità di CTR, il Click Love deve essere maggiore per le posizioni più in basso nella SERP e so che, a parità di posizione, il Click Love deve essere maggiore per le risorse su cui è stato osservato un CTR maggiore.
Con questo obiettivo, la formula più semplice che si può tirar fuori è una semplicissima moltiplicazione, ovvero:
[latex]\text{Click Love} = \text{CTR} \cdot \text{Posizione media}[/latex]
Applicando questa semplice formula ai valori citati nella tabella di cui sopra, emerge che il concetto di fondo è corretto: i risultati più eclatanti mostrano un Click Love più alto (per avere dei valori moltiplicabili tra loro, ho tradotto le percentuali in un valore tra 0 ed 1. Dunque 30% è diventato 0,3):
| CTR | Posizione media | Click Love | Valutazione risultato |
|---|---|---|---|
| 0,3 | 1 | 0,3 | CTR plausibile per una prima posizione. Nulla di speciale. |
| 0,3 | 3 | 0,9 | CTR molto alto per una terza posizione. La risorsa è stata in grado di attrarre click ben oltre a quanto la semplice posizione giustificherebbe. |
| 0,3 | 6 | 1,8 | CTR estremamente improbabile per una risorsa in sesta posizione. Qualunque cosa quella risorsa stia facendo per meritare click, lo sta facendo incredibilmente bene! |
Ragionando su questa prima bozza della formula, che consiste in una banale moltiplicazione tra CTR e posizione media, si evince con una certa facilità che è possibile ottenere un Click Love di 0,3 in infiniti modi, per esempio con un CTR del 30% su una risorsa in prima posizione oppure con un CTR del 10% su una risorsa in terza posizione. In entrambe i casi un Click Love di 0,3 non evidenzia una particolare capacità di una risorsa ad attrarre click, perché è abbastanza plausibile attendersi un CTR del 30% per la prima posizione, così come un CTR del 10% per la terza posizione.
E dunque abbiamo trovato la nostra formula del Click Love. Dal punto di vista teorico funziona, è un indice che tiene conto sia del CTR sia della posizione media delle risorse, tutti contenti e bella lì.
Click Love: perplessità
In realtà questa prima formula individuata è molto semplice e già sento echeggiare in testa un paio di critiche, la prima solleversi dal volgo armato di torce e forconi, la seconda mossa da me stesso a me stesso medesimo.
La prima perplessità è di tipo generico ed è indirizzata al senso dell’operazione in sé. “Enrico, la formula è troppo semplice e inadeguata. Le SERP sono soggette a fin troppi fenomeni che possono influenzare il click degli utenti: la personalizzazione e Universal Search e le immagini che attraggono l’occhio e le inserzioni AdWords e il Knowledge Graph e i One Box e la geolocalizzazione e la rava e la fava.”
E’ indubbio che esistano innumerevoli fenomeni che influenzano il click degli utenti, tuttavia non bisogna dimenticare qual è l’obiettivo del Click Love: eliminare (o quantomeno minimizzare) l’incognita del cambio di posizione dalla complessa valutazione di quanto una risorsa invita al click.
Il Click Love è dunque un primo passo in avanti per allontanarsi dall’inadeguato CTR, fin troppo soggetto a cambiamenti a seconda di eventuali cambi di posizione in SERP. Il Click Love non è né diventerà mai un indice perfetto ma per certo è migliore di un semplice CTR quando si devono comparare i risultati registrati su due diversi periodi, perché minimizza l’influenza di una variabile (la posizione della risorsa) che potrebbe inficiare l’intero test.
La seconda perplessità la pongo io e riguarda il modo in cui i click degli utenti vengono solitamente distribuiti lungo la SERP.
Nella prima bozza di formula che ho ideato, il CTR viene semplicemente moltiplicato per la posizione media. Questo significa che, a parità di CTR, è stato deciso che ad una risorsa in seconda posizione va attribuito un peso doppio rispetto ad una risorsa in prima posizione. Allo stesso modo, ciò che sta in quarta posizione “pesa” il quadruplo di ciò che sta in prima posizione e ciò che sta in ottava posizione viene moltiplicato per otto, ovvero otto volte quello che sta in prima posizione.
Questi valori con cui moltiplicare il CTR crescono quindi in modo del tutto lineare e sarebbero adeguati al nostro scopo solo se la distribuzione in SERP dei click degli utenti seguisse effettivamente un andamento altrettanto lineare. Nella realtà però le cose stanno in modo molto diverso: diverse ricerche hanno mostrato che i click sulle SERP si distribuiscono seguendo una curva che è tutto fuorché lineare.
Di conseguenza, una semplice moltiplicazione del CTR per la posizione media rappresenta una semplificazione eccessiva: nonostante sia corretto attribuire un Click Love maggiore alle risorse che stanno più in basso, il “quanto” il Click Love debba essere maggiore allo scendere della posizione è un punto importante della questione, che separa una formula grezza da una formula accettabile.
Per far le cose per bene, la formula del Click Love deve tener conto di una tipica distribuzione dei click sulle SERP.
Click Love: maggiore precisione
A costo di sembrare troppo perentoreo, sono costretto a fare un’affermazione un po’ drastica: tutte le ricerche che sono state effettuate da illustri brand e aziende sulla distribuzione dei click sulle SERP sono fuorvianti. Ma proprio tutte.
Sia ben chiaro, non sto mettendo in dubbio la validità degli approcci seguiti nel misurare i CTR o la correttezza dei risultati. Dico solo che il modo in cui i risultati sono stati presentati al pubblico, ovvero sotto forma di barbare semplificazioni, non può che generare applicazioni fuorvianti.
La misurazione del CTR sulle SERP è un argomento complesso e un’attività di difficile esecuzione. La complessità dei fenomeni che regolano l’interazione degli utenti con i risultati delle ricerche dei motori è talmente alta che qualsiasi tentativo di calcolare medie su una grande quantità di osservazioni genera risultati che descrivono male la realtà.
Diverse aziende che si sono cimentate nella misurazione del CTR, per esempio, hanno prodotto degli orrendi mischioni in cui il CTR veniva calcolato su query di ogni tipo. Già questo approccio genera risultati privi di significato, perché la distribuzione dei click varia considerevolmente a seconda delle diverse tipologie di query: navigazionale, informativa, branded/unbranded, di specifici settori merceologici, ecc.
Nonostante la ricerca che io giudico meglio portata avanti sia quella di Mec, riassunta in un’infografica che vi invito a leggere, la quantità dei dati pubblicati non era sufficiente per le mie necessità. Pertanto ho dovuto ripiegare sui dati misurati e pubblicati in uno studio analogo, svolto da Optify nel 2010 [PDF].
Per ottenere una formula di Click Love che tenesse conto della distribuzione dei click nelle SERP, ho proceduto come segue:
1) Ho preso i dati di Optify, che riguardavano i CTR registrati sulle prime venti posizioni delle SERP, ed ho preso in considerazione solo i CTR delle prime dieci posizioni;
2) Ho disegnato i valori dei CTR su un piano cartesiano;
3) Ho individuato una formula (a) che disegnasse una curva che segue approssimativamente l’andamento dei valori di CTR. La formula (a) è dunque in grado di descrivere la distribuzione dei click sulla SERP:
4) Ho creato una seconda formula (b) che moltiplicata ad (a) restituisse una costante. In altre parole la formula (b) annulla gli effetti di (a), che è la formula che rappresenta la distribuzione dei click. Se masticate un minimo di matematica, saprete che (b) si può ottenere semplicemente facendo il reciproco di (a):
5) Ho generalizzato (b) eliminando una costante che mi era servita solo per far combaciare inizialmente la curva con i dati dei CTR misurati da Optify, ottenendo infine un’espressione da usare come moltiplicatore del CTR per ricavare il Click Love: [latex]b = x^{1.22}[/latex]
La formula definitiva del Click Love, che stavolta è in grado di tener conto di una realistica distribuzione dei click sulle SERP, è dunque: [latex]\text{Click Love} = \text{CTR} \cdot \text{Posizione media}^n[/latex]
, dove “n” è una variabile che nell’esempio specifico dei dati di Optify equivale a 1.22 ma che può essere modificata a discrezione per meglio adattarsi alla distribuzione di click di una specifica query o classe di query. Per esempio, valori più alti di “n” sono adatti per calcolare il Click Love di query che registrano percentuali di click molto alte sui primi risultati (es: query brandizzate) mentre valori più bassi di “n” sono adatti per calcolare il Click Love di query che registrano click più omogeneamente distribuiti lungo i dieci risultati della SERP.
Sulla base dei dati di Optify, che delle diverse tipologie di query ha fatto un minestrone, il valore di “n” è pari a 1.22, che può essere considerato un valore da usare per query generiche, che inducono l’utente a cliccare più di un risultato della SERP.
E dunque formula trovata, obiettivo raggiunto, giochino matematico appagante e bella lì.
Click Love: vantaggi
La formula del Click Love può essere usata ogni qualvolta è necessario determinare un indice di “figosità” o “attrazione di click” di una specifica risorsa che appare in SERP, col vantaggio che l’indice mantiene una propria coerenza anche nel caso in cui la risorsa cambi di posizione durante il periodo di monitoraggio.
Nel caso in cui vogliate studiare in che modo le modifiche allo snippet di una risorsa hanno influito sui click che essa ha raccolto, il Click Love rappresenta un indice meno problematico e più affidabile del semplice CTR.
Click Love: come usarlo
L’indice è perfetto per fare comparazioni tra la capacità di attrarre click di una risorsa misurata prima e dopo una modifica al poprio snippet.
Va precisato che la formula è in grado di minimizzare gli eventuali effetti nefasti di un cambio di posizione della risorsa monitorata ma che non tiene conto di giganteschi sconquassi alla SERP. Se una SERP viene improvvisamente modificata da Google aggiungendo nuovi elementi in grado di attrarre l’attenzione dell’utente, non c’è formula che possa mantenere la propria validità. In fase di svolgimento di un test, quindi, rimangono opportune e valide le varie condizioni che sono elencate in cima all’articolo, con l’eccezione della condizione riguardante il cambio di posizione.
L’applicazione del Click Love ad un test come quello descritto ad inizio del post è del tutto analoga a quanto fatto col CTR: si calcola prima il Click Love di ciascuna giornata e si fa poi una comparazione tra il Click Love medio registrato sul periodo precedente alla modifica dello snippet ed il Click Love medio registrato sul periodo successivo alla modifica.
Una seconda applicazione del Click Love può essere quella di comparare tra loro i Click Love di diversi risultati nella stessa SERP, posto che si possiedano i dati di CTR e posizione media dei due snippet che si desidera comparare.
Sia che la comparazione avvenga tra due diverse risorse, sia che avvenga sulla stessa risorsa monitorata su due periodi differenti, bisogna fare attenzione ad attribuire il giusto valore ad “n” e a mantenerlo durante tutte le comparazioni effettuate su risultati della stessa query o tipologia di query.
Come già accennato, un valore di “n” attorno a 1.2 riesce a descrivere una distribuzione dei click tipica di query che inducono l’utente a visitare diversi risultati. Per query branded, “n” può superare 2 e personalmente consiglio di assegnargli un valore compreso tra 2 e 3.
Non fatevi ingannare dall’apparente difficoltà ad individuare un valore di “n” adatto, perché non esistono valori “giusti” o “sbagliati”: l’aspetto realmente importante è che “n” venga definito una volta per ciascuna tipologia di query e mantenuto per sempre.
Click Love: come non usarlo
Non potete usare il Click Love per comparare la “figosità” di snippet/risorse che appaiono per query diverse: sarebbe un’azione semplicemente priva di senso.
Il Click Love non è un indice di qualità intrinseco di una risorsa o snippet, ma solo un indice di quanto la risorsa è in grado di attrarre click all’interno di un contesto specifico, ovvero il contesto di una query o di un insieme di query dalle caratteristiche simili.
In pura teoria sarebbe possibile calcolare il Click Love medio di una grande quantità di query e poi monitorarlo nel corso del tempo, per esempio per osservare gli effetti di una vasta attività di copywriting dei titoli. Sebbene possibile, io sconsiglio di applicare il Click Love a grandi accozzaglie di query troppo diverse tra loro, per esempio query di settori diversi o di tipologia diversa (navigazionale, transazionale, ecc.). Questo genere di comparazioni acquista un po’ più senso classificando le query per tipologia, ma il mio consiglio rimane quello di non farsi prendere dalla voglia di usarlo su larga scala.
Per generalizzare: è una pessima idea usare il Click Love per vedere chi ce l’ha più lungo/alto/figo/duro.
Click Love: limiti
Il Click Love è lontano dall’essere perfetto. Questa affermazione va ben oltre la considerazione che non è possibile produrre una formula perfetta ma significa che anche dal punto di vista matematico è stato scelto di affidarsi ad una modalità di distribuzione dei CTR che presenta delle rigidità: può variare al variare di “n” ma rimane comunque di tipo esponenziale.
Per come la formula è stata presentata in questo articolo, inoltre, vale la pena di sottolineare di nuovo come essa sia dedicata solo ai primi dieci risultati della SERP. E’ facile estendere la formula ai risultati successivi al decimo, persino tenendo conto del fenomeno che vede il primo risultato della seconda pagina pià cliccato dell’ultimo risultato della prima pagina. Ma essendo il Click Love poco più di un “proof of concept”, lascerò eventuali estensioni al lettore.
Conclusioni
Test sul CTR effettuato, modalità di approccio descritte, idee su nuovo KPI condivise. Bella lì.
P.S.
Pensavo che sarebbe interessante parlare di argomenti simili in qualche evento. Giusto per dire.
come mai non hai fatto l’esperimento sulla meta description, che non dovrebbe portare a modifiche del posizionamento ?
@andrea: avevamo puntato sul testo del tag title in quanto ben più visibile e corto rispetto a quello del meta description. La sua brevità permette di raggiungere anche gli utenti che non si soffermano a leggere gli snippet ma che si limitano a scansire velocemente la pagina.
complimenti, test molto “scientifico” ma spiegato molto semplicemente. Ora metto in saccoccia e ripeto questo test 🙂
In passato ho fatto test dai risultati incoraggianti semplicemente modificando il titolo da minuscolo in maiuscolo. Certo però con l’arricchimento dello snippet, oramai il maiuscolo non spicca più in serp come una volta.
Quando torni su Marte portami con te a fare un giro…
Non è che il nostro apertivo dell’altra sera ti ha dato degli spunti per fare un test, tipo questo? 😉
@Alessio: no, il test è stato svolto mesi fa. 😛
Dovrebbe far parte del bagaglio di base di qualsiasi SEO la certezza che rendere più attraente l’abbinata title/description faccia salire i tassi di CTR nelle SERP. Ma hai fatto bene a ricordarlo 😉
Seguendo le tue riflessioni, ad esempio a me è venuto in mente che sarebbe sempre cosa buona e giusta dare uno sguardo (e magari fare qualche test mirato) in AdWords per stabilire le migliori abbinate possibili titoli/descrizioni, prima di ottimizzare un sito.
Ti suggerisco invece una denominazione diversa per il tuo indice (click love non mi sembra molto intuitivo/esplicativo).
Potrebbe essere click-worthy index o indice di attrattività di un risultato in SERP (in inglese funziona sempre meglio! Non c’è nulla da fare :-).
Purtroppo la denominazione non l’ho inventata io, ma non mi risulta che nessuno ci abbia mai però prima d’ora costruito sopra un indice calcolato matematicamente.
Buon pro ti faccia. Ma anche no 😉
@Gianpaolo: confesso che essendo il Click Love semplicemente un “proof of concept”, non sono stato troppo tempo a pensare al nome da attribuirgli. In realtà chiunque potrà usare questo studio iniziale per tirar fuori un indice migliore e attribuirgli un nome più descrittivo. 🙂
Il click è “na sveltina” alla fine dei conti, io lo rinominerei “click-lust” o “click-frenzy” 😀
Ottima idea, complimenti davvero! Tra l’altro approfitto per ringraziarti di quanto pubblichi sul blog, apprezzo molto il tuo approccio scientifico alla SEO.
Sono tuttavia perplesso su un aspetto: nella ricerca di Optify c’è la dimostrazione che in base a diverse variabili (nel lavoro presentato per esempio volume di ricerca e “valore” della parola chiave) la curva cambia sensibilmente (e con essa le percentuali di CTR sulle singole posizioni).
Questo significa che i dati usati per il calcolo del Click Love sono una media generale, che però può avere valori anche molto diversi nei singoli casi (infatti il valore della mediana riportata in una della tabella è sensibilmente diverso dalla media).
Non ritieni che questa variabilità renda il valore del Click Love non applicabile realmente senza conoscere i dati di CTR della “propria” SERP?
Tengo a precisare che questa considerazione, ammesso e non concesso che sia corretta, nulla toglie al ragionamento che invece ritengo essere una piccola perla.
@Bobo: è assolutamente corretto quanto dici. Questa è la ragione per la quale i dati di Optify sono stati usati solo per ottenere una prima curva, per definizione generica e non rappresentativa di specifiche query/SERP, che viene poi modificata dal parametro “n”.
Il parametro “n” non è una panacea perché permette di modificare la curva in modo un po’ troppo rigido, tuttavia assolve al compito che mi ero dato, ovvero ottenere un parametro che a seconda del proprio valore permettesse di distinguere le curve di distribuzione tipiche delle query brand (accumulo dei click in cima alla SERP) dalle curve di distribuzione non-brand. Il modo in cui il cambio di distribuzione avviene è più chiaro quando si gioca interattivamente con il parametro “n”:
http://www.youtube.com/watch?v=Hxfr8TnJwgU
Grazie!
Approfitto ancora della tua disponibilità per chiederti di che software si tratta quello che usi per l’analisi matematica del post.
Grazie ancora.
@Bobo: ho usato un tool molto semplice che si limita a disegnare funzioni: https://www.desmos.com/calculator
Grazie!